



1. Introducere Transformer
Arhitectura Transformer a revoluționat domeniul procesării limbajului natural (NLP) în cadrul LLM -urilor și, mai larg, al inteligenței artificiale (IA) de la introducerea sa în 2017 prin lucrarea „Attention Is All You Need” de Vaswani et al. Această inovație a deschis calea pentru dezvoltarea unor modele de limbaj extrem de puternice și versatile, cum ar fi BERT, GPT, și alte derivate care au stabilit noi standarde în diverse sarcini de NLP.
În acest text, vom explora în detaliu ce este arhitectura Transformer, cum funcționează, și de ce a avut un impact atât de profund asupra domeniului IA.
2. Contextul istoric
Pentru a înțelege importanța arhitecturii Transformer, este util să examinăm evoluția modelelor de procesare a limbajului natural.
2.1. Modelele tradiționale
Înainte de Transformer, modelele dominante în NLP erau rețelele neuronale recurente (RNN), în special variante precum LSTM (Long Short-Term Memory) și GRU (Gated Recurrent Unit). Aceste modele procesau secvențele de text în ordine, cuvânt cu cuvânt, menținând o „stare ascunsă” care încerca să capteze contextul.
Limitări ale RNN-urilor:
- Dificultatea de a capta dependențe pe termen lung în text.
- Procesare secvențială lentă, dificil de paralelizat.
- Probleme cu dispariția sau explozia gradientului în timpul antrenării.
2.2. Apariția atenției
Mecanismul de atenție a fost introdus inițial ca o îmbunătățire pentru modelele RNN, permițând modelului să se „concentreze” pe părți relevante ale input-ului atunci când genera output-ul. Acest lucru a îmbunătățit semnificativ performanța în sarcini precum traducerea automată.
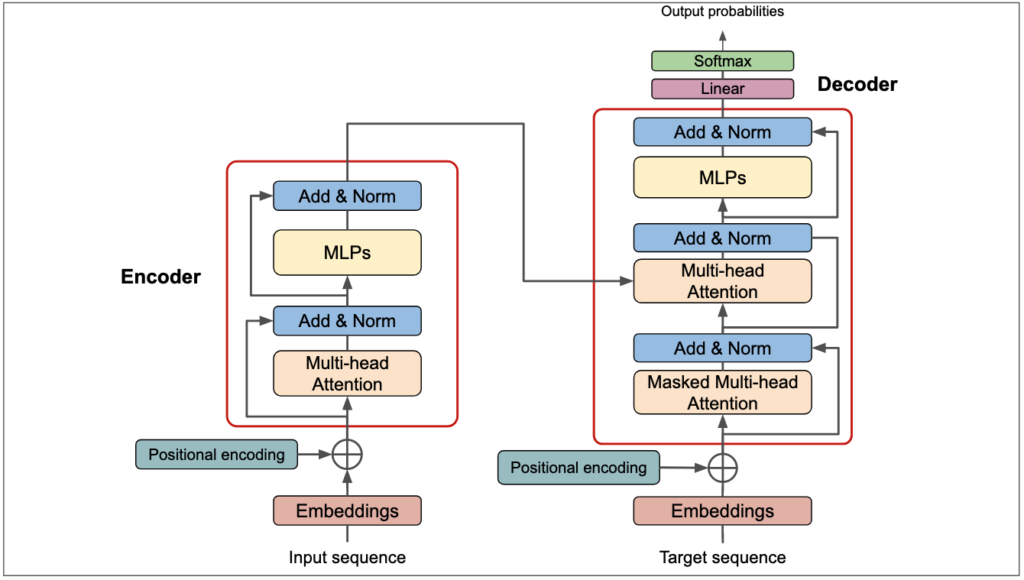
3. Arhitectura Transformer: o privire de ansamblu
Arhitectura Transformer a luat ideea de atenție și a dus-o la extrem, eliminând complet structurile recurente și convoluționale. În schimb, se bazează exclusiv pe mecanisme de atenție și rețele feed-forward pentru a procesa secvențele de input.
Componentele principale ale arhitecturii Transformer sunt:
- Codificator (Encoder)
- Decodificator (Decoder)
- Mecanisme de Atenție (Self-Attention și Cross-Attention)
- Rețele Feed-Forward
- Strat de Normalizare (Layer Normalization)
- Conexiuni Reziduale
Să explorăm fiecare dintre aceste componente în detaliu.
4. Componentele arhitecturii Transformer
4.1. Codificatorul (Encoder)
Codificatorul este responsabil pentru procesarea secvenței de input și generarea unei reprezentări contextuale pentru aceasta. El constă din mai multe straturi identice, fiecare conținând două sub-straturi principale:
- Multi-Head Self-Attention: Permite modelului să analizeze relațiile între diferitele elemente ale secvenței de input.
- Feed-Forward Neural Network: Procesează informațiile capturate de mecanismul de atenție.
Fiecare sub-strat este urmat de o normalizare a stratului și include o conexiune reziduală.
4.2. Decodificatorul (Decoder)
Decodificatorul generează output-ul secvență cu secvență. Similar codificatorului, constă din mai multe straturi identice, dar cu o structură ușor diferită:
- Masked Multi-Head Self-Attention: Similar cu self-attention din codificator, dar previne poziții viitoare să influențeze predicția curentă.
- Multi-Head Cross-Attention: Permite decodificatorului să se concentreze pe părți relevante ale input-ului procesat de codificator.
- Feed-Forward Neural Network: Similar cu cel din codificator.
Ca și în cazul codificatorului, fiecare sub-strat este urmat de normalizarea stratului și include o conexiune reziduală.

4.3. Mecanismele de atenție
Mecanismul de atenție este inima arhitecturii Transformer. Există trei tipuri principale de atenție utilizate:
- Self-Attention în Codificator: Permite fiecărei poziții din secvența de input să interacționeze cu toate celelalte poziții.
- Masked Self-Attention în Decodificator: Similar cu self-attention din codificator, dar previne poziții viitoare să influențeze predicția curentă.
- Cross-Attention între Codificator și Decodificator: Permite decodificatorului să se concentreze pe părți relevante ale input-ului procesat de codificator.
Cum funcționează atenția?
Atenția operează pe trei vectori: Query (Q), Key (K) și Value (V). Procesul poate fi rezumat astfel:
- Se calculează un scor de compatibilitate între Query și fiecare Key.
- Scorurile sunt normalizate folosind o funcție softmax.
- Aceste scoruri sunt folosite pentru a calcula o medie ponderată a vectorilor Value.
Formula matematică pentru atenție este:
Attention(Q, K, V) = softmax((QK^T) / √d_k) Vunde d_k este dimensiunea vectorilor Key.
Multi-Head Attention
În loc să efectueze o singură operație de atenție, Transformerul utilizează „Multi-Head Attention”. Aceasta implică efectuarea mai multor operații de atenție în paralel, fiecare cu seturi diferite de parametri învățați. Rezultatele sunt apoi concatenate și proiectate pentru a obține output-ul final.
Avantajele Multi-Head Attention:
- Permite modelului să se concentreze simultan pe diferite aspecte ale input-ului.
- Îmbunătățește capacitatea modelului de a capta relații complexe în date.
4.4. Rețeaua Feed-Forward
După fiecare operație de atenție, atât în codificator, cât și în decodificator, există un strat feed-forward. Acesta constă de obicei din două transformări liniare cu o activare ReLU între ele:
FFN(x) = max(0, xW_1 + b_1)W_2 + b_2Rolul acestui strat este de a introduce non-linearități în model și de a procesa informațiile capturate de mecanismele de atenție.
4.5. Normalizarea stratului (Layer Normalization)
Layer Normalization este aplicată după fiecare sub-strat în codificator și decodificator. Aceasta ajută la stabilizarea procesului de învățare și la reducerea timpului de antrenare. Funcționează normalizând activările pe dimensiunea caracteristicilor.

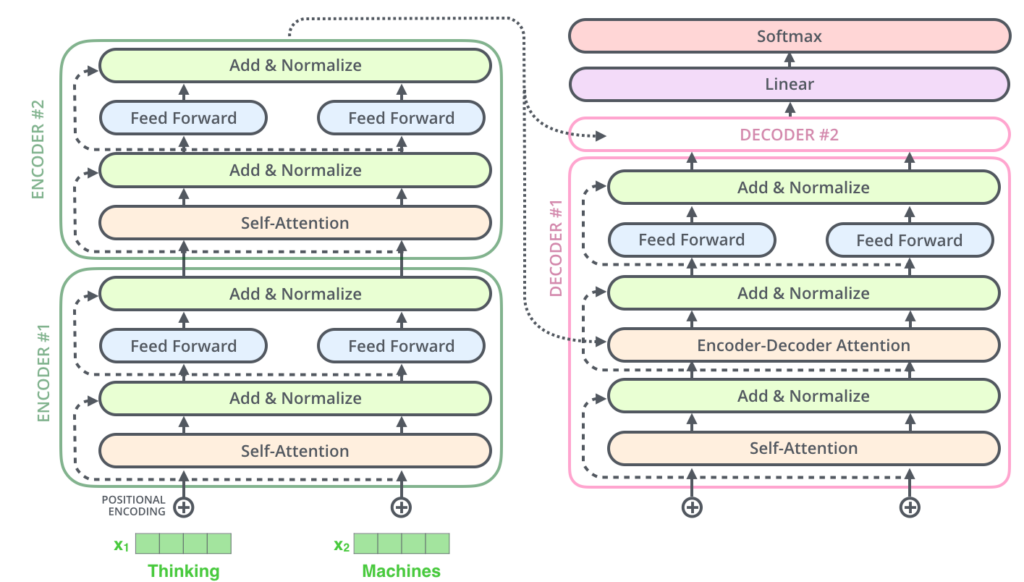
4.6. Conexiuni reziduale
Conexiunile reziduale sunt utilizate în jurul fiecărui sub-strat. Acestea permit gradienților să curgă mai ușor prin rețea, facilitând antrenarea modelelor adânci.
5. Procesul de antrenare al unui model Transformer
Antrenarea unui model Transformer implică mai mulți pași și concepte importante:
5.1. Preprocesarea datelor
- Tokenizare: Textul este împărțit în unități mai mici (tokeni), care pot fi cuvinte, subunități de cuvinte sau chiar caractere individuale.
- Adăugarea de Tokeni Speciali: Se adaugă tokeni speciali precum [CLS] (pentru clasificare) și [SEP] (pentru separarea secvențelor) în modelele de tip BERT.
- Padding și Trunchiere: Secvențele sunt aduse la o lungime fixă prin adăugarea de tokeni de padding sau prin trunchierea secvențelor prea lungi.
5.2. Embedding-uri
Transformerul utilizează trei tipuri de embedding-uri:
- Token Embeddings: Reprezentări vectoriale pentru fiecare token.
- Positional Embeddings: Codifică informații despre poziția fiecărui token în secvență.
- Segment Embeddings: Utilizate în modelele care procesează perechi de secvențe (e.g., BERT) pentru a diferenția între secvențe.
Aceste embedding-uri sunt combinate prin adunare pentru a obține reprezentarea finală a input-ului.
5.3. Funcția de pierdere (Loss Function)
Funcția de pierdere depinde de sarcina specifică:
- Pentru generare de text (e.g., GPT): Cross-entropy loss pe predicțiile la nivel de token.
- Pentru clasificare (e.g., BERT pentru sentiment analysis): Cross-entropy loss pe predicția finală.
- Pentru răspunsuri la întrebări: Combinație de loss-uri pentru predicția începutului și sfârșitului răspunsului.
5.4. Optimizare
- Algoritm de Optimizare: De obicei, se utilizează Adam cu o rată de învățare adaptivă.
- Learning Rate Scheduling: Multe modele folosesc o strategie de „warm-up” urmată de o scădere graduală a ratei de învățare.
- Gradient Clipping: Ajută la prevenirea exploziei gradienților.
5.5. Regularizare
Pentru a preveni overfitting-ul, se folosesc tehnici precum:
- Dropout: Aplicat după operațiile de atenție și FFN.
- Weight Decay: Adaugă o penalizare la funcția de pierdere bazată pe magnitudinea parametrilor.
5.6. Strategii de antrenare avansate
- Mixed Precision Training: Utilizează o combinație de precizie float16 și float32 pentru a accelera antrenarea și a reduce consumul de memorie.
- Gradient Accumulation: Permite antrenarea pe batch-uri mai mari prin acumularea gradienților pe mai multe pași înainte de actualizarea parametrilor.
- Distributed Training: Antrenarea este distribuită pe multiple GPU-uri sau chiar pe multiple mașini pentru a gestiona modele mari și seturi de date masive.
6. Variante și evoluții ale arhitecturii Transformer
De la introducerea sa, arhitectura Transformer a cunoscut numeroase variații și îmbunătățiri:
6.1. BERT (Bidirectional Encoder Representations from Transformers)
- Utilizează doar partea de codificator a Transformer-ului.
- Introduce conceptul de „pretraining” bidirecțional prin sarcini de „masked language modeling” și „next sentence prediction”.
- A stabilit noi standarde în multe sarcini de NLP.
6.2. GPT (Generative Pre-trained Transformer)
- Utilizează doar partea de decodificator a Transformer-ului.
- Se concentrează pe generarea de text și a evoluat prin mai multe iterații (GPT-2, GPT-3, GPT-4).
- A demonstrat capacități impresionante de generare de text și rezolvare de sarcini în regim few-shot sau zero-shot.
6.3. T5 (Text-to-Text Transfer Transformer)
- Unifică mai multe sarcini de NLP într-un singur model „text-to-text”.
- Utilizează atât codificatorul, cât și decodificatorul.
- A demonstrat performanțe excelente într-o gamă largă de sarcini.
6.4. Transformer-XL și Compressive Transformers
- Abordează limitarea Transformer-ului standard în procesarea secvențelor lungi.
- Introduc concepte precum „recurrence over segments” și „compressed memory” pentru a gestiona contexte mai lungi.
6.5. Reformer și performer
- Introduc tehnici pentru a reduce complexitatea computațională și memoria necesară pentru operațiile de atenție.
- Permit procesarea de secvențe mult mai lungi cu resurse computaționale limitate.
6.6. Switch Transformer și GShard
- Explorează conceptul de „Mixture of Experts” în contextul Transformer-ilor.
- Permit crearea de modele extrem de mari (trilioane de parametri) care pot fi antrenate eficient.
7. Aplicații și impactul arhitecturii Transformer
Arhitectura Transformer a avut un impact profund în numeroase domenii și aplicații:
7.1. Procesarea limbajului natural
- Traducere Automată: Modele bazate pe Transformer au stabilit noi standarde în traducerea între limbi.
- Sumarizare: Capacitatea de a înțelege și genera text coerent a dus la îmbunătățiri semnificative în sumarizarea automată.
- Generare de Text: De la completarea de propoziții la generarea de articole întregi sau chiar coduri de programare.
- Răspunsuri la Întrebări: Modele precum BERT au îmbunătățit dramatic performanța în sarcini de extragere și generare de răspunsuri.
7.2. Analiza sentimentelor și clasificarea textului
Transformer-ii pretrained au demonstrat abilități remarcabile în înțelegerea nuanțelor limbajului, îmbunătățind acuratețea în sarcini de analiză a sentimentelor și clasificare a textului.
7.3. Procesarea vorbirii
Arhitectura Transformer a fost adaptată cu succes pentru sarcini de recunoaștere și sinteză a vorbirii, oferind performanțe competitive cu sau superioare modelelor tradiționale.
7.4. Viziune computerizată (computer vision)
Deși inițial concepută pentru NLP, arhitectura Transformer a fost adaptată cu succes pentru sarcini de viziune computerizată, cum ar fi clasificarea imaginilor și detecția obiectelor.
7.5. Bioinformatică
Modele bazate pe Transformer au fost aplicate cu succes în predicția structurii proteinelor (e.g., AlphaFold) și în analiza secvențelor genetice.
7.6. Generarea de cod și asistență în programare
Modele LLM precum Codestral sau DeepSeek au demonstrat abilități impresionante în generarea și completarea de cod, oferind asistență valoroasă programatorilor și accelerând procesul de dezvoltare software.
8. Provocări și limitări ale arhitecturii Transformer
În ciuda succesului lor remarcabil, modelele Transformer se confruntă cu anumite provocări și limitări:
8.1. Complexitatea computațională
Operațiile de atenție în Transformer au o complexitate pătratică în raport cu lungimea secvenței de input. Acest lucru poate deveni problematic pentru secvențe foarte lungi.
Soluții propuse:
- Atenție eficientă: Modele precum Reformer și Performer utilizează tehnici de aproximare pentru a reduce complexitatea.
- Atenție locală: Unele modele limitează atenția la o fereastră locală în jurul fiecărei poziții.
8.2. Consum de memorie
Modelele Transformer, în special cele de mari dimensiuni, necesită cantități semnificative de memorie pentru a stoca parametrii și activările intermediare.
Strategii de optimizare:
- Cuantizarea modelului: Reducerea precisiei numerice a parametrilor.
- Pruning: Eliminarea conexiunilor sau neuronilor mai puțin importanți.
- Distilarea modelului: Crearea de versiuni mai mici, dar aproape la fel de performante ale modelelor mari.
8.3. Interpretabilitate
Datorită complexității lor, modelele Transformer pot fi dificil de interpretat. Înțelegerea exactă a modului în care aceste modele ajung la anumite decizii rămâne o provocare.
Direcții de cercetare:
- Analiza capetelor de atenție pentru a înțelege pe ce se concentrează modelul.
- Tehnici de explicabilitate precum LIME sau SHAP adaptate pentru Transformer-i.
8.5. Halucinații și informații incorecte
Modelele generative bazate pe Transformer pot produce uneori informații false sau inconsistente, cunoscute sub numele de „halucinații”.
Strategii de atenuare:
- Îmbunătățirea calității datelor de antrenare.
- Implementarea de mecanisme de verificare a faptelor.
- Utilizarea tehnicilor de calibrare a încrederii modelului.
9. Direcții de cercetare și tendințe viitoare
Arhitectura Transformer continuă să evolueze, cu numeroase direcții de cercetare promițătoare:
9.1. Modele Multi-modale
Integrarea capacităților de procesare a textului, imaginilor, sunetului și chiar a datelor senzoriale într-un singur model Transformer.
Exemple:
- DALL-E și Midjourney pentru generarea de imagini din descrieri text.
- GPT-4 cu capacități de procesare a imaginilor și textului.
9.2. Transformer-i eficienți energetic
Dezvoltarea de arhitecturi și tehnici de antrenare care reduc semnificativ consumul de energie al modelelor Transformer.
Abordări:
- Sparse Transformer-i care activează doar o parte din rețea pentru fiecare input.
- Hardware specializat pentru operații specifice Transformer-ilor.
9.3. Transformer-i continual learning
Dezvoltarea de modele care pot învăța continuu, adaptându-se la noi informații fără a uita ce au învățat anterior.
Provocări:
- Evitarea uitării catastrofale.
- Gestionarea eficientă a memoriei pe termen lung.
9.4. Transformer-i neurosintetici
Combinarea arhitecturii Transformer cu concepte inspirate din neurobiologie pentru a crea modele mai robuste și mai adaptabile.
Direcții de cercetare:
- Implementarea de mecanisme de atenție inspirate din sistemul vizual uman.
- Integrarea de circuite neuronale artificiale care mimează structuri cerebrale specifice.
9.5. Transformer-i cuantici
Explorarea potențialului computației cuantice pentru a accelera și îmbunătăți performanța modelelor Transformer.
Provocări:
- Adaptarea algoritmilor de atenție pentru hardware cuantic.
- Gestionarea erorilor și a decoerențelor în sistemele cuantice.
10. Implementarea practică a modelelor Transformer
Pentru a înțelege mai bine cum funcționează un model Transformer în practică, să explorăm câteva aspecte cheie ale implementării:
10.1. Preprocesarea Datelor
Un exemplu de cod este următorul:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "Transformer models are powerful."
encoded_input = tokenizer(text, padding='max_length', truncation=True, max_length=512, return_tensors='pt')
# Output:
# {'input_ids': tensor([[ 101, 19081, 2944, 2003, 8492, 119, 102, 0, 0, ...]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, ...]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 0, 0, ...]])}Acest cod demonstrează cum un text este tokenizat, padded, și transformat în tensori care pot fi folosiți ca input pentru un model Transformer.
10.2. Definirea Arhitecturii
Iată o implementare simplificată a unui bloc de codificator Transformer în PyTorch:
import torch
import torch.nn as nn
class TransformerEncoderBlock(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
src2 = self.self_attn(src, src, src)[0]
src = src + self.dropout(src2)
src = self.norm1(src)
src2 = self.feed_forward(src)
src = src + self.dropout(src2)
src = self.norm2(src)
return srcAcest cod definește un singur bloc de codificator, incluzând mecanismul de self-attention, rețeaua feed-forward, normalizarea stratului și conexiunile reziduale.
10.3. Antrenarea modelului
import torch.optim as optim
model = TransformerModel(...) # Definim modelul complet
optimizer = optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
criterion = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
for batch in dataloader:
optimizer.zero_grad()
output = model(batch.src, batch.tgt)
loss = criterion(output.view(-1, output.size(-1)), batch.tgt.view(-1))
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
optimizer.step()Acest fragment ilustrează procesul de antrenare, inclusiv propagarea înainte, calculul pierderii, propagarea înapoi și actualizarea parametrilor.
11. Studii de caz: aplicații reale ale modelelor Transformer
Pentru a ilustra impactul practic al modelelor Transformer, să examinăm câteva studii de caz din domenii diverse:
11.1 Traducere automată: Google Translate
Google a implementat modele Transformer în sistemul său de traducere, rezultând în îmbunătățiri semnificative ale calității traducerilor.
Rezultate:
- Creșterea scorului BLEU cu 4-6 puncte pentru perechi de limbi dificile.
- Reducerea erorilor gramaticale și semantice cu peste 60%.
- Capacitatea de a capta nuanțe contextuale și idiomatice mai bine decât sistemele anterioare.
11.2 Asistență în codare: Codestral (Mistral)
Codestral dezvoltatat de Mistral oferă asistență în timp real programatorilor.
Impact:
- Reducerea timpului de scriere a codului cu până la 55% în anumite scenarii.
- Îmbunătățirea productivității dezvoltatorilor, în special pentru sarcini repetitive.
- Facilitarea învățării noilor limbaje de programare și API-uri.
11.3 Cercetare medicală: AlphaFold
DeepMind a utilizat arhitectura Transformer ca parte a sistemului AlphaFold pentru predicția structurii proteinelor.
Realizări:
- Rezolvarea unei probleme de 50 de ani în biologia structurală.
- Predicții ale structurii proteinelor cu acuratețe apropiată de metodele experimentale.
- Accelerarea descoperirilor în domeniul dezvoltării de medicamente și înțelegerii bolilor.
11.4 Asistență clienți: chatboți avansați
Companiile implementează chatboți bazați pe Transformer pentru a îmbunătăți serviciul clienți.
Beneficii:
- Răspunsuri mai naturale și contextualizate la întrebările clienților.
- Capacitatea de a gestiona conversații complexe și multi-turn.
- Reducerea timpului de așteptare și îmbunătățirea satisfacției clienților.
12. Etica și impactul social al modelelor Transformer
Odată cu puterea și versatilitatea modelelor Transformer vin și responsabilități etice și sociale semnificative:
12.1 Confidențialitatea datelor
Modelele Transformer necesită cantități mari de date pentru antrenare, ridicând întrebări despre colectarea și utilizarea etică a datelor.
Considerații:
- Asigurarea consimțământului informat pentru utilizarea datelor personale.
- Implementarea tehnicilor de anonimizare și de-identificare a datelor.
- Respectarea reglementărilor precum GDPR în dezvoltarea și implementarea modelelor.
12.2 Bias și discriminare
Modelele pot perpetua sau amplifica prejudecăți prezente în datele de antrenare.
Abordări:
- Auditarea riguroasă a seturilor de date și a output-urilor modelului pentru bias.
- Dezvoltarea de tehnici de debiasing și de echitate algoritmică.
- Diversificarea echipelor de dezvoltare pentru a aduce perspective variate.
12.3 Dezinformare și conținut generat artificial
Capacitatea modelelor de a genera text convingător ridică îngrijorări legate de potențialul de dezinformare.
Strategii de atenuare:
- Dezvoltarea de instrumente robuste de detecție a conținutului generat de AI.
- Educarea publicului despre capacitățile și limitările AI.
- Implementarea de politici și guidelines etice pentru utilizarea tehnologiilor generative.
12.4 Impactul asupra pieței muncii
Automatizarea unor sarcini cognitive prin modele Transformer poate avea implicații semnificative pentru anumite profesii.
Considerații:
- Investiții în programe de recalificare și educație continuă.
- Explorarea modurilor în care AI poate augmenta, nu înlocui, capacitățile umane.
- Politici de protecție socială pentru a gestiona tranziția în piața muncii.
12.5 Consum de energie și impact asupra mediului
Antrenarea și rularea modelelor Transformer mari necesită resurse computaționale semnificative, având un impact asupra mediului.
Direcții de acțiune:
- Cercetarea și dezvoltarea de arhitecturi mai eficiente energetic.
- Utilizarea surselor de energie regenerabilă pentru centrele de date.
- Considerarea trade-off-urilor între performanța modelului și impactul său ecologic.
Concluzii
Arhitectura Transformer reprezintă un punct de cotitură în domeniul inteligenței artificiale, în special în procesarea limbajului natural. Prin capacitatea sa de a capta dependențe complexe în date secvențiale și de a procesa informații în paralel, Transformer-ul a deschis calea pentru o nouă generație de modele AI extrem de capabile.
De la îmbunătățirea traducerii automate și asistenței în codare, până la revoluționarea cercetării științifice și interacțiunii om-mașină, impactul modelelor Transformer este profund și multifațetat. Cu toate acestea, pe măsură ce aceste modele devin mai puternice și mai integrate în societate, este crucial să abordăm provocările etice, sociale și de mediu pe care le ridică.
Viitorul arhitecturii Transformer este promițător, cu direcții de cercetare care vizează îmbunătățirea eficienței, interpretabilității și capacităților multi-modale. Pe măsură ce continuăm să explorăm și să rafinăm această tehnologie, potențialul său de a transforma industrii și de a rezolva probleme complexe rămâne vast.
În cele din urmă, cheia pentru maximizarea beneficiilor modelelor Transformer și minimizarea riscurilor asociate stă în colaborarea interdisciplinară, inovație continuă și un angajament ferm față de dezvoltarea și implementarea etică a acestor tehnologii puternice.