


1. Introducere: Apariția și Evoluția Inteligenței Artificiale
Inteligența Artificială (IA) reprezintă una dintre cele mai fascinante și revoluționare dezvoltări tehnologice ale epocii noastre. Conceptul de IA a apărut în mijlocul secolului XX, odată cu progresele în domeniul științei computerelor și al teoriei informației. Ideea de bază era de a crea mașini capabile să „gândească” și să efectueze sarcini care, în mod tradițional, necesitau inteligență umană.
1.1. Începuturi
În 1950, Alan Turing a propus celebrul „Test Turing” ca o modalitate de a evalua capacitatea unei mașini de a demonstra un comportament inteligent echivalent cu cel al unui om. Acest test a devenit un punct de reper în dezvoltarea IA.

În anii ’50 și ’60, cercetătorii au făcut progrese semnificative în domenii precum procesarea limbajului natural, rezolvarea problemelor și recunoașterea tiparelor. Unul dintre primele succese notabile a fost programul „Logic Theorist”, creat în 1955 de Allen Newell, Herbert A. Simon și Cliff Shaw, care putea demonstra teoreme matematice.
1.2. Dezvoltări ulterioare
Pe parcursul deceniilor următoare, IA a cunoscut perioade de entuziasm urmate de pauze extrem de lungi, când finanțarea și interesul au scăzut din cauza limitărilor tehnologice și a așteptărilor nerealiste. Cu toate acestea, progresele constante în hardware și software au menținut domeniul în viață.
În anii ’80 și ’90, abordările bazate pe reguli și sistemele expert au dominat domeniul IA. Aceste sisteme utilizau seturi complexe de reguli „if-then” pentru a lua decizii și rezolva probleme în domenii specifice.
1.3. Revoluția învățării automate
Odată cu creșterea puterii de calcul și disponibilitatea unor cantități mari de date, învățarea automată a devenit din ce în ce mai proeminentă în anii 2000. Aceasta a marcat o schimbare fundamentală în abordarea IA, trecând de la sisteme bazate pe reguli programate manual la sisteme care pot „învăța” din date.
Rețelele neuronale, un concept introdus încă din anii ’50, au revenit în prim-plan sub forma „învățării profunde” (deep learning). Această tehnică, inspirată de structura creierului uman, s-a dovedit deosebit de eficientă în sarcini precum recunoașterea imaginilor, procesarea limbajului natural și jocuri.
1.4. Era LLM-urilor
În ultimul deceniu, am asistat la apariția și evoluția rapidă a Modelelor Lingvistice de Mari Dimensiuni (Large Language Models – LLM).
Acestea reprezintă un vârf al progreselor în învățarea profundă, procesarea limbajului natural și puterea de calcul.
Furnizorii de putere de calcul precum NVIDIA fac posibile miliardele de calcule pe secundă necesare procesării neuronale paralele care dâ energie LLM-urilor.
LLM-urile au deschis noi orizonturi în ceea ce privește capacitatea mașinilor de a înțelege și genera limbaj uman într-un mod care părea de domeniul science-fiction-ului cu doar câțiva ani în urmă.
2. Ce sunt LLM-urile?
LLM-urile (Large Language Models) sunt modele de inteligență artificială concepute pentru a înțelege, genera și manipula limbajul uman într-un mod care se apropie de capacitățile umane. Aceste modele sunt „mari” atât în ceea ce privește numărul de parametri pe care îi conțin (care poate ajunge la sute de miliarde), cât și în ceea ce privește cantitatea de date cu care sunt antrenate.
2.1. Caracteristici principale ale LLM-urilor
- Dimensiune: LLM-urile sunt caracterizate prin numărul lor imens de parametri, care le permite să capteze nuanțe complexe ale limbajului.
- Antrenare pe date masive: Aceste modele sunt antrenate pe seturi de date enorme, care pot include cărți, articole, pagini web și alte surse de text.
- Versatilitate: LLM-urile pot fi folosite pentru o gamă largă de sarcini lingvistice, de la traducere și rezumare la generare de text și răspunsuri la întrebări.
- Învățare auto-supervizată: Multe LLM-uri sunt antrenate folosind tehnici de învățare auto-supervizată, ceea ce înseamnă că pot învăța din date care nu au necesitat intervenția unui factor uman.
- Transfer learning: Capacitatea de a fi ajustate pentru sarcini specifice după o antrenare inițială pe un set de date general.
2.2. Arhitectura de bază
Majoritatea LLM-urilor moderne sunt bazate pe arhitectura Transformer, introdusă de Google în 2017. Această arhitectură a revoluționat procesarea limbajului natural datorită capacității sale de a gestiona dependențe pe termen lung în text și de a procesa texte paralel, mai degrabă decât secvențial.

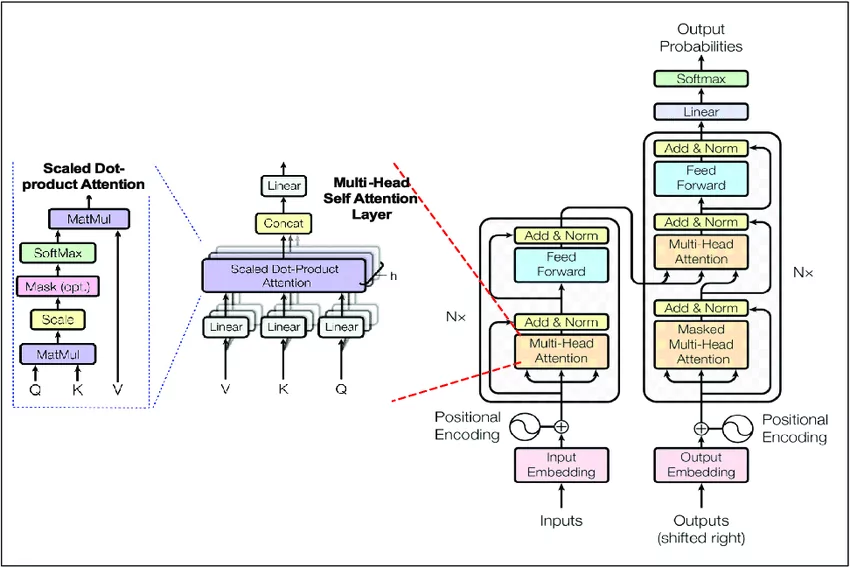
Componentele cheie ale arhitecturii Transformer includ:
- Mecanismul de atenție: Permite modelului să se concentreze pe părți relevante ale input-ului atunci când generează output.
- Codificator / Decodificator: Deși unele LLM-uri folosesc doar componenta de decodificator, această structură permite modelelor să proceseze input-ul și să genereze output-ul.
- Straturi feed-forward: Aceste straturi procesează informațiile capturate de mecanismele de atenție.
- Normalizare și conexiuni reziduale: Ajută la stabilizarea antrenării și permit modelelor să facă analize profunde.
2.3. Cum funcționează LLM-urile
La bază, LLM-urile funcționează predicând următorul cuvânt (sau token) într-o secvență, bazându-se pe contextul oferit de cuvintele anterioare. Acest proces, aparent simplu, permite modelului să capteze o gamă largă de cunoștințe și capacități lingvistice:
- Înțelegerea contextului: Modelul învață să înțeleagă contextul la diferite niveluri, de la structura gramaticală de bază până la nuanțe semantice complexe.
- Generarea de text: Prin predicția succesivă a următorului cuvânt probabil, modelul poate genera texte coerente și contextuale.
- Adaptabilitate: LLM-urile pot fi ajustate pentru sarcini specifice prin ajustare sau prin furnizarea de instrucțiuni în prompt.
- Memorare implicită: În timpul antrenării, modelul „memorează” informații din setul de date, putând să le acceseze și să le utilizeze în generarea de răspunsuri.
3. Construirea și antrenarea LLM-urilor
Procesul de construire și antrenare a unui LLM este complex, consumator de resurse și necesită o expertiză considerabilă în domeniul învățării automate și al procesării limbajului natural.
3.1. Pregătirea datelor
Primul pas în crearea unui LLM este colectarea și pregătirea unui set de date masiv și divers:
- Colectarea datelor: Datele pot proveni din surse variate, inclusiv cărți, articole, pagini web, forumuri online și alte resurse textuale.
- Curățarea datelor: Este esențial să se elimine conținutul nepotrivit, duplicatele și datele de calitate slabă.
- Tokenizarea: Textul este împărțit în unități mai mici, numite tokeni, care pot fi cuvinte, părți de cuvinte sau caractere individuale.
- Augmentarea datelor: În unele cazuri, setul de date poate fi îmbogățit prin tehnici precum traducerea automată sau parafrazarea.
3.2. Proiectarea arhitecturii
Alegerea și configurarea arhitecturii modelului este crucială:
- Dimensiunea Modelului: Se decide numărul de parametri, care poate varia de la câteva sute de milioane la sute de miliarde.
- Arhitectura Transformer: Se configurează numărul de straturi, dimensiunea capului de atenție și alte hiperparametri.
- Optimizări arhitecturale: Se pot implementa tehnici precum „sparse attention” sau „mixture of experts” pentru a îmbunătăți eficiența.
3.3. Procesul de antrenare
Antrenarea unui LLM este o sarcină computațională intensivă:
- Hardware: Se utilizează clustere mari de GPU-uri sau TPU-uri pentru a procesa cantități masive de date.
- Strategii de antrenare: Se folosesc tehnici precum „gradient accumulation” și „mixed precision training” pentru a gestiona limitările de memorie și a accelera antrenarea.
- Optimizatori: Se aleg și se configurează algoritmi de optimizare precum Adam sau AdaFactor.
- Learning rate scheduling: Se implementează strategii de ajustare a ratei de învățare pe parcursul antrenării.
- Regularizare: Se aplică tehnici pentru a preveni overfitting-ul, cum ar fi „dropout” sau „weight decay”.
3.4. Monitorizare și ajustare
Pe parcursul antrenării, performanța modelului este monitorizată constant:
- Metrici de evaluare: Se urmăresc metrici precum perplexitatea și acuratețea pe seturi de date de validare.
- Ajustarea hiperparametrilor: În funcție de performanță, se pot ajusta diverși hiperparametri.
- Checkpoint-uri: Se salvează versiuni intermediare ale modelului pentru a permite reluarea antrenării sau evaluarea ulterioară.
3.5. Fine-Tuning (ajustare) și specializare
După antrenarea inițială, modelul poate fi specializat pentru sarcini specifice:
- Transfer Learning: Modelul pre-antrenat este adaptat pentru sarcini specifice folosind seturi de date mai mici și specializate.
- Few-Shot Learning: Se explorează capacitatea modelului de a învăța din exemple limitate.
- Prompt engineering: Se dezvoltă tehnici pentru a ghida modelul să performeze sarcini specifice prin formularea adecvată a prompt-urilor.
3.6. Evaluare și testare
Înainte de lansare, modelul trece prin etape riguroase de evaluare:
- Benchmark-uri standard: Se testează performanța pe seturi de date și sarcini standard în domeniul NLP.
- Teste de robustețe: Se evaluează comportamentul modelului în situații neașteptate sau cu input-uri neobișnuite.
- Evaluarea etică: Se analizează potențialele prejudecăți sau comportamente problematice ale modelului.
- Testare în lumea reală: Se efectuează teste pilot în scenarii de utilizare reale.
4. Aplicații practice LLM-urilor
LLM-urile au deschis noi posibilități în numeroase domenii, revoluționând modul în care interacționăm cu tehnologia și procesăm informația. Iată câteva exemple și studii de caz care ilustrează potențialul acestor modele:
4.1. Asistență și suport clienți
Agențiii AI pot folosi unul sau mai multe LLM-uri pentru diferite sarcini în cadrul conversațiilor cu factorii umani (clienți/angajați).
Spre exemplu un chat bot poate să fie integrat în platforma online a unui website și să:
- ofere asistență clienților în găsirea de informații detaliate despre un produs conform criteriilor specificate de clienți;
- să dea relații despre istoricul cumpărăturilor sau starea livrării anumitor produse;
- să ajute vânzătorii cu informații despre produse;
- să ajute angajații cu provire la procedurile interne ale companiei;
- să ajute la procesul de analiză internă a informațiilor;
- să genereze rapoarte și analize.
Asistentul AI poate fi integrat și în comunicarea audio/video prin voice recognition și computer vision. Astfel modelul AI poate șă:
- discute în limbaj natural cu angajații și să răspundă la întrebări referitoare la informațiile pe care a fost antrenat (informațiile interne ale firmei);
- poate să vorbească la telefon cu clienții, să facă programări sau să ofere asistență generală;
- să urmărească video un proces și să identiice neconcordanțele (de exemplu să urmărească împachetarea produselor care urmează să fie livrate și să identiice produsele deteriorate).
4.2. Educație și e-learning
Un model AI poate fi utilizat ca un profesor personal
Modelul AI poate identifica probleme principale ale elevului, caracteristicile lui personale privind felul cum învață și poate genera un program personalizat de învâțare și materialele necesare pentru îmbunățățirea rezultatelor.
Astfel, se pot genera materiale audio/video pe care elevul le poate înțelege mai bine, modelul poate conversa cu elevul fără o limită de timp, până când elevul înțelege toate aspectele problemelor și poate genera și teste adaptate progresului individual al studentului.
4.3. Cercetare și analiză de date
LLM pot analiza și sintetiza documentele de orice tip, fie el text, audio sau video
Modelele AI pot genera rezumate ale documentelor, pot extrage rapid informații pe baza unor instrucțiuni sau pur și simplu dialog cu utilizatorii, pot căuta în bazele de date locale sau în cloud situații relevante pentru utilizatori,
Folosite adecvat, LLM-urile pot identifica similarități și prin urmare face clasificări ale datelor putând fi utilizate pe un volulum foarte mare de informații care cercetat manual ar necesita un mare consum de resurse.
4.4. Creație și generare de conținut
Dezvoltarea software, text, audio sau video
Dacă în cazul utilizării LLM-urilor ca asistenți de dezvoltare software situația e mai simplă, în cazul generării de text, audio sau video se poate pune problema deținerii drepturilor de autor. Este o carte scrisă de un LLM o operă literară? Poate o imagine generată de calculator să câștige un concurs de fotografie?

Însă tehnologia evoluează și rezultatele sunt extraordinare.
4.4. Automatizări și robotică
LLM-urile însuflețesc roboții
Una din marile probleme ale constorilor avansați de roboți identificarea unei metode prin care un robot să poată evolua singur și să se adapteze la mediul înconjurător cu factori care se schimbă mereu.
Programarea directă a sarcinilor era o tentativă de rezolvare a acestei probleme, dar nu poți să prevezi orice situație care poate să apară.
LLM-urile au fost întroduse în acționarea roboților tocmai din acest motiv: acum aceștia pot să interacționeze cu mediul înconjutător prin computer vision (și să identifice și să plaseze spațial obiectele înconjurătoare), să interacționeze cu cei din jur prin recunoaștere vocală în orice fel de limbă și să poată genera răspunsuri și acțiuni concludente pe baza deep-learning-ului și instrucțiunilor cu care LLM-ul a fost antrenat.