



În era digitală, tehnologia de recunoaștere vocală automată (ASR – Automatic Speech Recognition) a devenit o componentă esențială a interacțiunii om-mașină. De la asistenți vocali până la subtitrare automată, sistemele de ASR au ajuns aproape de performanța umană în limbi cu resurse mari, cum ar fi engleza, chineza sau spaniola. Totuși, această evoluție a lăsat în urmă majoritatea celor peste 7000 de limbi din lume – în special cele cu puține vorbitori, numite „limbi de tip lung-tail”. Aceste limbi, care includ dialecte locale, limbile indigene sau limbile minoritare, sunt adesea lipsite de orice formă de tehnologie vocală, ceea ce le exclude din beneficiile accesului digital.
Proiectul Omnilingual ASR reprezintă o revoluție în acest domeniu, oferind primul sistem de recunoaștere vocală multilingvă pe scară largă, conceput pentru extensibilitate și accesibilitate. În loc să fie limitat la un set fix de limbi, acest sistem permite comunităților să adauge limbile lor proprii cu doar câteva eșantioane de înregistrări vocale, fără a necesita cunoștințe avansate sau resurse computaționale mari. Această abordare nu doar că extinde acoperirea ASR la peste 1600 de limbi – inclusiv peste 500 care nu au fost niciodată susținute de nicio platformă – ci și pune accentul pe colaborare etică, partajare deschisă și inclusivitate digitală.
Abilitățile de recunoaștere vocală împreună cu cele de recunoaștere visuală (computer vision) transformă modelele generative clasice de tip text, în unele multimodale capabilă să relaționeze mult mai bine cu lumea reală.
1. Modelele AI de recunoaștere Vocală
Sistemele moderne de recunoaștere vocală utilizează algoritmi avansați de inteligență artificială pentru a converti vorbirea umană în text cu o acuratețe impresionantă.
Printre cele mai performante modele de recunoaștere vocală disponibile astăzi se numără Whisper de la OpenAI, un sistem open-source antrenat pe peste 680000 de ore de date audio multilingve. Acesta oferă capabilități remarcabile de transcripție în peste 90 de limbi, stabilind noi standarde în domeniul recunoașterii vocale.
Google Speech-to-Text reprezintă o altă soluție puternică de recunoaștere vocală, integrată în numeroase aplicații și servicii. Tehnologia Google folosește rețele neuronale profunde pentru a procesa vorbirea în timp real, oferind suport pentru peste 125 de limbi și variante regionale.
Microsoft Azure Speech Service se remarcă prin precizia sa în recunoașterea vocală personalizată, permițând companiilor să adapteze modelele pentru terminologie specifică industriei. Sistemul de recunoaștere vocală al Microsoft include funcții avansate precum identificarea vorbitorilor și analiza sentimentelor.
Amazon Transcribe și IBM Watson Speech to Text completează paleta soluțiilor enterprise de recunoaștere vocală, fiecare aducând caracteristici distinctive precum transcrierea automată a conversațiilor telefonice sau suportul pentru jargon medical și legal.
Modelele moderne de recunoaștere vocală beneficiază de arhitecturi Transformer și tehnici de învățare profundă, care permit înțelegerea contextului și gestionarea accentelor diverse. Aceste progrese fac ca recunoașterea vocală să fie din ce în ce mai precisă, cu rate de eroare care scad continuu.
Aplicațiile practice ale tehnologiilor de recunoaștere vocală sunt vaste: de la asistentele virtuale și subtitlarea automată, până la accesibilitate pentru persoane cu dizabilități și automatizarea documentării medicale. Pe măsură ce cercetarea avansează, recunoașterea vocală va continua să revoluționeze comunicarea om-mașină.
2. Omnilingual ASR: recunoaștere vocală open source și adaptabilă
Traditional, dezvoltarea unui sistem de recunoaștere vocală pentru o limbă nouă presupune colectarea și etichetarea a mii de ore de înregistrări vocale, proces care este atât costisitor, cât și exclusiv pentru instituții cu resurse mari.
Acest model a dus la o disparitate profundă între limbi cu resurse și cele fără, lăsând în urmă comunități întregi. În schimb, Omnilingual ASR adoptă un nou paradigma: zero-shot generalization – capacitatea de a recunoaște o limbă nouă fără antrenament specific.
Această abordare este posibilă datorită unui antrenament în mare scară pe o colecție de date extrem de diversă și largă, combinând surse publice cu înregistrări colectate prin parteneriate compensate cu comunități locale. Modelul a fost antrenat pe o bază de date de peste 12 milioane de ore de vorbire, acoperind peste 1600 de limbi, cu o varietate semnificativă de dialecte, condiții de înregistrare (camere, străzi, telefoane mobile) și variații de vârstă și gen ale vorbitorilor. Această diversitate este esențială pentru a învăța reprezentări de speech robuste, care pot generaliza la limbi necunoscute în antrenament.

Pe plan tehnic, sistemul utilizează o arhitectură encoder–decoder inspirată de modelele de limbaj mare (LLM – Large Language Models), cu un decoder care încearcă să înțeleagă contextul lingvistic în mod similar ca un om.
Encoderul, bazat pe self-supervised learning (ex: XLS-R), este antrenat pe 7 miliarde de parametri, permițând o înțelegere profundă a structurii fonetice și semantice a vorbirii. Cheia succesului este faptul că modelul învață nu doar să recunoască sunete, ci și să înțeleagă relațiile dintre ele în contexte lingvistice diverse. Acest lucru permite o performanță remarcabilă chiar și în condiții extreme de resurse reduse – adică atunci când există doar câteva minute de înregistrare pentru o limbă. Evaluările automate arată că chiar și varianta mică de 300M de parametri depășește performanța modelului Whisper large-v3 pe majoritatea seturilor de testare, măsurată prin CER (Character Error Rate).
3. Înțelegerea și evaluarea performanței în condiții reale
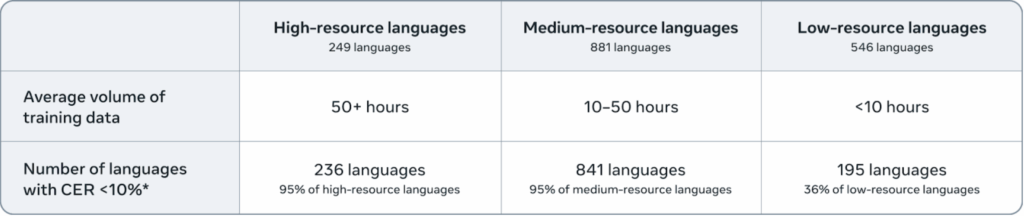
Performanța Omnilingual ASR a fost testată pe o varietate de benchmarkuri, inclusiv MMS-lab, Common Voice și seturi de date spontane din regiuni diverse (Africa, Asia de Sud-Est, America Latină). Rezultatele sunt clare: sistemul oferă o creștere semnificativă în comparație cu modelele anterioare, mai ales în cazul limbilor cu puține resurse.
De exemplu, pentru limbi precum Cham, Yabem sau Garifuna, care au fost anterior lipsite de ASR, sistemul a atins rate de eroare sub 40% – un nivel care permite utilizare practică în aplicații simple. Mai important, modelul demonstrează o generalizare puternică – poate recunoaște corect o limbă nouă doar după ce a fost expus la câteva exemple în timpul inferenței (in-context learning), fără antrenament suplimentar. Această capacitate este esențială pentru comunități care doresc să adauge o limbă nouă într-un singur pas.
Un aspect crucial este că performanța zero-shot nu poate încă egala cea a unui model antrenat în mod complet pe o limbă, dar oferă o cale mult mai scalabilă și etică pentru extinderea acoperirii. În contrast cu modelele anterioare care necesitau mii de ore de etichetare și resurse mari, Omnilingual ASR permite oricui – un profesor, un activitist comunitar, un student – să contribuie la dezvoltarea tehnologiei pentru orice fel de limbă. De asemenea, sistemul este disponibil sub formă de familie de modele: de la variante mici (300M) pentru dispozitive cu putere redusă (telefoane, tablette) până la modele mari (7B) pentru aplicații de înaltă precizie. Această gamă asigură accesibilitate la toate nivelurile tehnologice.
4. Etica și colaborarea comunitară în dezvoltarea tehnologiei
Un aspect esențial al proiectului Omnilingual ASR este accentul pus pe etică și colaborare. În trecut, colectarea de date vocale a fost adesea criticată pentru exploatarea comunităților, lipsa consimțământului informaționat sau riscul de supraveghere. Pentru a evita aceste probleme, echipa de cercetare a dezvoltat un model de parteneriat cu comunități locale, în care participanții sunt compensați pentru înregistrările lor.
Aceste parteneriate sunt gestionate prin platforme precum Common Voice sau proiecte locale precum African Next Voices sau Digital Umuganda. De asemenea, toate înregistrările sunt colectate cu consimțământul clar al vorbitorilor, iar informațiile personale sunt excluse (PII – Personally Identifiable Information). Participanții sunt încurajați să înregistreze într-un mod natural, fără a fi supuși unor întrebări care ar putea fi neplăcute sau inapropiate cultural.
În plus, sistemul este open-source, ceea ce înseamnă că modelele, instrumentele și codul sunt disponibile public pentru oricine. Acest lucru reduce bariera de intrare pentru cercetători, dezvoltatori și comunități care doresc să dezvolte aplicații pentru limbi locale. Nu mai este nevoie de cunoștințe avansate de învățare automată sau de acces la clustere de calcul costisitoare. De exemplu, un activitist într-o comunitate indigenă din Amazon poate folosi o versiune ușoară a modelului pe un telefon mobil pentru a crea un sistem de transcriere a vorbirii în limba sa. Acest model de dezvoltare deschisă nu doar că promovează inovația, dar și asigură că tehnologia este controlată de cei care o folosesc, nu de corporații mari.
5. Impactul social și viitorul recunoașterii vocale multilingve
Recunoașterea vocală multilingvă open source are un impact profund asupra societății. Fără acces la ASR, comunitățile vorbitoare de limbi minoritare sunt excluse de la instrumente de bază precum: dictarea vocală, căutarea pe internet, subtitrarea video sau serviciile de accesibilitate pentru persoanele cu dizabilități vizuale.


Omnilingual ASR aduce aceste tehnologii la nivelul tuturor, promovând echitatea digitală. În plus, permite păstrarea și revitalizarea limbilor în pericol de dispariție, transformându-le dintr-o tradiție orală într-un spațiu digital activ. Proiectele precum VAANI sau KenCorpus au deja demonstrat cum datele colectate în mod etic pot duce la dezvoltarea de resurse de înaltă calitate.
În viitor, Omnilingual ASR poate fi extins pentru a include și recunoașterea emoțiilor, dialecte regionale sau interacțiuni multilingve în timp real. Cu o bază de date în continuă creștere și o comunitate de dezvoltatori activă, sistemul are potențialul de a deveni o infrastructură de bază pentru o internet multilingvă, echitabilă și inclusivă. Acest proiect nu este doar o realizare tehnică, ci o promisiune: că tehnologia poate fi construită nu doar pentru a fi eficientă, ci și pentru a fi corectă, etică și accesibilă tuturor.
6. Utilizarea practică Omnilingual ASR
Cea mai simplă utilizare este prin folosirea codului Python într-un mediu separat:
# using pip pip install omnilingual-asr # using uv uv add omnilingual-asr
Pentru început putem afîșa toate limbile disponibile:
from omnilingual_asr.models.wav2vec2_llama.lang_ids import supported_langs
# Print all supported languages
print(f"Total supported languages: {len(supported_langs)}")
print(supported_langs)
# Check if a specific language is supported
if "eng_Latn" in supported_langs:
print("English (Latin script) is supported!")
Pentru traducere vom folos următorul cod:
from omnilingual_asr.models.inference.pipeline import ASRInferencePipeline pipeline = ASRInferencePipeline(model_card="omniASR_LLM_7B") audio_files = ["/path/to/eng_audio1.flac", "/path/to/deu_audio2.wav"] lang = ["eng_Latn", "deu_Latn"] transcriptions = pipeline.transcribe(audio_files, lang=lang, batch_size=2)
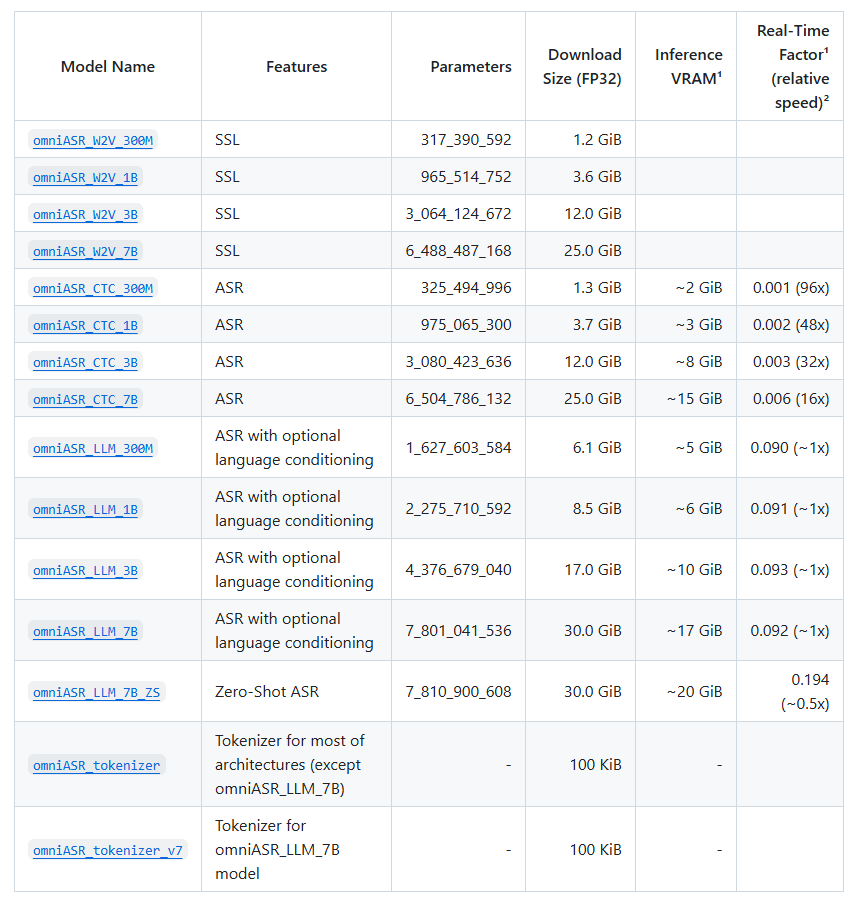
Omnilingual ASR vine în mai multe variante, de capacități diferite, dar și cu necesar de resurse divers:

7. Concluzie
Omnilingual ASR reprezintă un pașaport pentru o lume digitală multilingvă, în care nicio limbă nu mai este lăsată în urmă. Prin combinarea unui antrenament masiv, arhitecturi inovatoare și o abordare etică bazată pe colaborare, proiectul a reușit să extindă acoperirea ASR la peste 1600 de limbi, inclusiv peste 500 care nu au fost niciodată susținute în proiecte similare.
Performanța sa în condiții de resurse reduse și capacitatea de generalizare zero-shot fac posibilă participarea activă a comunităților. Fiind open-source și disponibil pentru diverse platforme, sistemul democratizează accesul la tehnologia vocală. În final, acest proiect nu doar că transformă tehnologia, ci și redefineste rolul cercetării într-un context global: nu ca o activitate elitistă, ci ca o forță de incluziune, echitate și schimbare pozitivă.