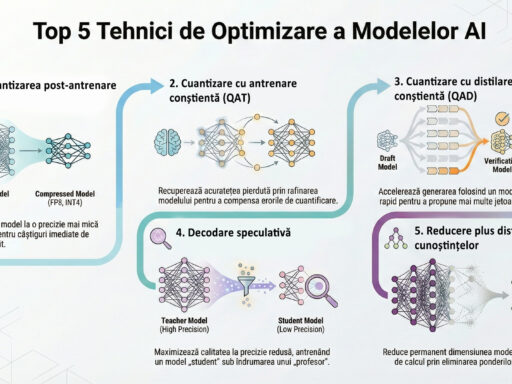
Într-un peisaj tehnologic în continuă evoluție, fine-tuning-ul modelelor lingvistice mari (LLM) este adesea prezentat ca o metodă rapidă și puternică de a injecta noi informații. Dar, în realitate, această abordare nu este întotdeauna cea mai eficientă și poate duce la rezultate nedorite. Articolul de față explică de ce fine-tuning-ul LLM-urilor este o pierdere de timp majoră pentru injectarea de cunoștințe (în 90% din cazurile despre care oamenii cred că este necesară).
1. LLM-urile ca ecosisteme de informații
Pentru a înțelege de ce fine-tuning-ul LLM-urilor avansate nu este la fel de simplu pe cât pare, este important să înțelegem modul în care rețelele neuronale, în special cele lingvistice, sunt antrenate de la zero.
La bază, rețelele neuronale sunt colecții imense de neuroni interconectați, fiecare având valori numerice (ponderi) care determină comportamentul lor. Inițial, aceste ponderi sunt stabilite aleatoriu – nu există informații codificate, nu există cunoștințe stocate, doar zgomot matematic.
Când antrenamentul începe, rețeaua primește date de intrare (cuvinte, propoziții, documente), face predicții (următorul cuvânt, completări de propoziții) și calculează cât de departe sunt aceste predicții de realitate.
Această diferență se numește pierdere (loss). Rețeaua utilizează apoi un proces cunoscut sub numele de retropropagare (backpropagation) pentru a ajusta incremental ponderile fiecărui neuron, reducând această pierdere. La începutul antrenamentului, acest lucru este ușor – neuronii stochează valori în esență aleatorii, deci actualizarea lor implică o pierdere minimă de informații utile.
Pe măsură ce antrenamentul progresează, rețeaua codifică progresiv tipare semnificative: nuanțe lingvistice, reguli sintactice, relații semantice și semnificații dependente de context. Neuronii evoluează din elemente de fundal anonime în elemente secundare importante, putând ajunge să se comporte în anumite stiluri sau evolueze precum adevărate personaje.
„Costul” actualizării unui neuron crește în LLM-urile antrenate, deoarece neuronii includ informații importante. Fine-tuning-ul, sau orice actualizare, este mai probabil să afecteze neuronii importanți, schimbând comportamentul așteptat.
Puteți observa acest lucru în cercetările privind siguranța. Așa cum am văzut anterior, alinierea schimbă distribuția bias-urilor (părtiniri) în rezultate, creând bias-uri noi și neașteptate, semnificativ diferite față de modelul de bază.
În esență, neuronii nu mai sunt neutri – fiecare actualizare riscă să suprascrie informații existente și valoroase, ducând la consecințe neintenționate în întreaga rețea. Un neuron poate fi important în mai multe sarcini, deci actualizarea lui va duce la implicații neașteptate.
2. Tendințe: inserția modulară de cunoștințe
Dacă fine-tuning-ul este o soluție riscantă, care este alternativa?
Răspunsul constă în modularitate și augmentare. Tehnici precum generarea augmentată prin recuperare (RAG), băncile de memorie externe și modulele adaptor oferă modalități mai robuste de a încorpora informații noi fără a suprascrie baza de cunoștințe a rețelei existente.
Generarea augmentată prin recuperare (RAG) utilizează baze de date externe pentru a augmenta cunoștințele în mod dinamic la momentul inferenței. Deși unii afirmă că RAG este depășit, rămâne în prezent cea mai fiabilă tehnică atunci când procesează cantități mari de date pentru întrebări și răspunsuri. Pentru sarcini de cunoaștere mai complexe, RAG-ul naiv poate fi insuficient, dar există tehnici avansate de recuperare și reprezentare care pot fi implementate pentru a crea performanțe mult mai puternice. RAG-ul poate fi folosit împreună cu protocolul MCP pentru a accesa mult mai ușor resursele organizației fără a fi necesar ca modelul să fie antrenat în mod explicit pe aceste date.
Modulele Adaptor și LoRA(Low-Rank Adaptation) inserează noi cunoștințe prin subrețele specializate, izolate, lăsând neuronii existenți intacti. Aceasta este o metodă ideală pentru sarcini precum formatarea, lanțuri specifice etc. – toate acestea nu necesită o actualizare completă a rețelei neuronale.
Prompting Contextual utilizează capacitățile preexistente ale modelului fără modificări permanente ale neuronilor. Prompting-ul corect este o abilitate cu un ROI foarte mare.
Aceste tehnici recunosc neuronii pentru ceea ce sunt cu adevărat: resurse finite, prețioase și dens împachetate, care ar trebui lăsate intacte ori de câte ori este posibil. Deși există mult mai multe tehnici, acestea sunt suficiente pentru majoritatea echipelor pentru a utiliza modelele AI (chiar și cele mai mici precum Gemma 3 de la Google) fără a avea nevoie de o expertiză extinsă într-un anumit domeniu.
3. Implicațiile practice și considerații
În loc să investim în fine-tuning costisitor și riscant, organizațiile ar trebui să se concentreze pe dezvoltarea de sisteme modulare. Acest lucru implică utilizarea RAG pentru a accesa surse externe de cunoștințe, implementarea de module adaptor pentru sarcini specifice și perfecționarea abilităților de prompting pentru a extrage informații relevante din modelele existente.
Această abordare oferă mai multe avantaje:
Flexibilitate sporită: modulele pot fi adăugate sau eliminate cu ușurință fără a afecta nucleul modelului.
Scalabilitate îmbunătățită: sistemele modulare pot fi extinse cu ușurință prin adăugarea de noi module.
Costuri reduse: evitarea fine-tuning-ului reduce costurile de calcul și de stocare.
Riscuri mai mici: suprascrierea cunoștințelor existente este evitată, reducând riscul de a introduce erori sau bias-uri nedorite.
4. Concluzie
Fine-tuning-ul nu este injectare de cunoștințe – este suprascriere de cunoștințe. Pentru LLM-urile avansate, neuronii nu mai sunt locuri neutre; sunt depozite dens interconectate de informații valoroase. Actualizarea lor iresponsabilă riscă daune catastrofale, invizibile.
Dacă obiectivul este crearea de sisteme adaptabile, scalabile și robuste, tratați fine-tuning-ul cu prudența cuvenită.
Folosiți soluții modulare care mențin integritatea bazei de cunoștințe a rețelei dumneavoastră. Altfel, pur și simplu demontați ecosistemul dumneavoastră atent construit de cunoștințe – neuron cu neuron.