Gemini 1.5 flash 8B este unul din cele mai mici, rapide și totdată eficiente modele LLM furnizate de Google, ideal pentru a fi utilizat ca motor pentru diferite aplicații AI.
1. Gemini 1.5 Flash 8B: O nouă eră în inteligența artificială
În peisajul în continuă evoluție al inteligenței artificiale, Google a făcut un pas semnificativ înainte cu lansarea seriei de modele Gemini 1.5, în special cu varianta Gemini 1.5 Flash 8B. Această nouă iterație a familiei de modele lingvistice mari (LLM) Gemini aduce îmbunătățiri substanțiale în ceea ce privește eficiența, viteza și capacitățile generale, marcând un punct de cotitură în domeniul AI.
Gemini 1.5 Flash 8B se remarcă prin dimensiunea sa redusă, având doar 8 miliarde de parametri, ceea ce îl face semnificativ mai compact decât multe alte modele de top din industrie. Cu toate acestea, în ciuda dimensiunii sale reduse, modelul demonstrează performanțe impresionante, rivalizând sau chiar depășind modele mult mai mari în anumite sarcini.
Una dintre cele mai notabile caracteristici ale Gemini 1.5 Flash 8B este viteza sa extraordinară de inferență. Datorită optimizărilor arhitecturale și tehnicilor avansate de antrenament, modelul poate procesa și genera text cu o viteză remarcabilă, oferind răspunsuri aproape instantanee în multe aplicații. Această viteză îmbunătățită deschide noi posibilități pentru implementarea AI în scenarii în timp real și aplicații interactive.
Eficiența computațională este un alt punct forte al Gemini 1.5 Flash 8B. Consumul redus de resurse permite implementarea modelului pe o gamă mai largă de dispozitive, inclusiv pe smartphone-uri și alte dispozitive cu putere de calcul limitată. Acest lucru democratizează accesul la tehnologia AI avansată și facilitează integrarea sa în diverse aplicații și servicii.
În ceea ce privește performanța, Gemini 1.5 Flash 8B excelează în diverse sarcini de procesare a limbajului natural. De la generarea de text și traduceri, până la rezumarea documentelor și răspunsul la întrebări complexe, modelul demonstrează o înțelegere nuanțată a contextului și poate produce rezultate coerente și relevante.
Un aspect important al seriei Gemini 1.5 este îmbunătățirea capacității de a procesa și genera conținut multimodal. Deși Gemini 1.5 Flash 8B este primordial un model de limbaj, acesta beneficiază de arhitectura avansată a seriei Gemini, care permite o mai bună înțelegere și corelare a informațiilor din diverse surse, inclusiv text, imagini și date structurate.
Seria Gemini 1.5 aduce, de asemenea, progrese semnificative în domeniul raționamentului și al rezolvării de probleme. Modelele din această serie, inclusiv Flash 8B, demonstrează o capacitate îmbunătățită de a înțelege și aplica concepte abstracte, de a face inferențe logice și de a aborda sarcini care necesită gândire critică.
În comparație cu predecesorii săi și cu alți competitori din industrie, Gemini 1.5 Flash 8B se distinge prin echilibrul său între performanță, eficiență și accesibilitate. Acest echilibru îl face deosebit de atractiv pentru dezvoltatori și companii care caută să implementeze soluții AI avansate fără a necesita resurse computaționale masive.
Cu toate acestea, este important de menționat că, în timp ce Gemini 1.5 Flash 8B reprezintă un progres semnificativ, el face parte dintr-o serie mai largă de modele Gemini 1.5, fiecare optimizat pentru anumite cazuri de utilizare și scenarii. Versiunile mai mari ale seriei pot oferi capacități și mai avansate pentru sarcini extrem de complexe sau specializate.
Gemini 1.5 Flash 8B și seria Gemini 1.5 în ansamblu marchează un pas important înainte în evoluția modelelor lingvistice mari. Prin combinarea eficienței, vitezei și performanței într-un pachet compact, aceste modele deschid noi posibilități pentru inovație în domeniul AI, promițând să transforme modul în care interacționăm cu tehnologia și procesăm informațiile în viitorul apropiat.
2. Aplicație personală: traducerea unei cărți din limba engleză în limba română cu Gemini 1.5 Flash 8B
Ne place să citim și din comoditate căutăm cârți în format electronic. De obicei pentru cârțile noi editurile oferă și posibilitatea achiziției unui ebook, dar pentru cărțile mai vechi posibilitățile sunt destul de limitate: uneori gâsim cartea scantă (dar nu OCR-izată) sau găsim doar variantele în engleză.

În exemplul din acest articol ne propunem să prelucrăm o carte în format epub, în limba engleză și să o traducem cât mai rapid și cu interacțiuni minime într-o variantă în limba romană numai bună de instalam pe Kindle.
Ca sursă am ales o carte pentru care nu mai există drepturi de autor, care este disponibilă gratuit prin Proiectul Gutenberg.
2.1. Planificare
Pentru traducerea cărții va trebui să parcurgem câteva etape:
- să extragem textul din formatul epub;
- să traducem textul;
- să salvâm textul și să îl reconvertim în formatul epub inițial;
- să adăugăm cartea în librăria personală Kindle.
Epub este un format de ebook-uri care are la bază fișiere HTML care conțin capitolele cărții.
2.2. Convertire Epub în HTML
Pentru a ajunge la capitole putem folosi librăria python:
pip install html_from_epubPrin rularea unui cod python simplu putem transforma cartea într-un director care conține secțiunile în format HTML:
>>> from html_from_epub import convert
>>> convert('path_to_file.epub')2.3. Prelucrarea HTML prin automatizare
Ar fi un pic prea încet dacă am face traducerea manual sau dacă am folosi serviciile gratuite de traducere, precum Google Translate, care în plus au și anumite limitări legate de mărimea materialului care trebuie procesat.
Desigur putem folosi diverse API-uri, dar ne mai lovim de o problemă și anume că textul pe care îl avem e în format HTML, adică conține tag-uri de tip <h2>, <p> sau diferite stiliuri și clase pe care am dori să le păstrăm.
Firesc, apare ideea de a folosi pentru această procesare un model LLM suficient de avansat și de rapid care să poată face o traducere fidelă în limba română, iar Google Gemini 1.5 Flash 8B pare exact soluția pe care o căutăm.
Gemini 1.5 Flash 8B care este oferit în mai multe variante de dezvoltare este un model mic (doar 8 miliarde de parametri) care oferă viteză foarte bună, un context generos de 1 milion de tokeni (care asigură coerență în executarea sarcinilor), preț mic și cel mai important pentru noi – este antrenat pentru limba română și poate genera un text corect scris gramatical.
Modelul Gemini 1.5 Flash 8B poate fi folosit prin API din Google Cloude Console (Google AI Studio), iar pentru aceste exemplu am ales o implementare prin serviciul de automatizări N8N.
Acest lucru ne scutește de scrierea codului de apelare a modelului Gemini 1.5 Flash 8B, tot procesul fiind executat printr-un webhook cu mai multe noduri în N8N.
Planul este următorul:
- să parcurgem toate paginile HTML;
- pentru fiecare pagină extragem conținutul HTML (nu ne interesează partea de header);
- pentru că pot să apară erori de traducere vom împărți textul în mai multe bucăți de dimensiuni acceptabile;
- fiecare bucată de text HTML o vom trimite la un webhook N8N care se va ocupa de traducerea ei folosind Gemini 1.5 Flash 8B și va răspunde cu textul prelucrat, dar tot în format HTML;
- dacă din diferite motive traducerea eșuează se reîncearcă traducerea bucății respective;
- în final textul tradus este reasamblat și salvat ca fișier HTML.
Un exemplu de cod Python este următorul (atenție, codul nu este optimizat ci scris mai degrabă cu scop explicativ):
import requests
import numpy as np
import time
url = "XXXXXXXXXXXXXXXXXXXXXXXX"
def tradu_capitol(capitol):
url_baza = "7528574217114712565_1259-h-"+ str(capitol) + ".htm.xhtml"
with open(url_baza, 'r', encoding='utf8') as f:
contents = f.read()
contents = contents.replace("—", "-")
contents_split1 =str(contents).split('<h2>')
contents_split2 =str(contents_split1[1]).split('</div>')
text_continut = "<h2>" + contents_split2[0]
text_continut_split = text_continut.split('<p')
texte = []
pozitie = 0
pozitie_curenta = 0
pozitie_maxima = len(text_continut_split)
#print(text_continut_split[1])
eroare_traducere = False
#facem split la text in chunkuri de 50 de p-uri
while pozitie < pozitie_maxima and eroare_traducere == False:
chunk = ""
pozitie_chunk_maxim = pozitie + 50
if pozitie_chunk_maxim > pozitie_maxima:
pozitie_chunk_maxim = pozitie_maxima
#print(pozitie)
#print(pozitie_chunk_maxim)
for i in range(pozitie, pozitie_chunk_maxim):
if i != 0:
chunk = chunk + "<p"
chunk = chunk + text_continut_split[i]
# Process the chunk here
texte.append(chunk)
# dupa parsare trecem la urmatorul chunk
pozitie = pozitie_chunk_maxim +1
numar_requests = len(texte)
#numar_requests = 1
text_final = contents_split1[0]
for i in range (0, numar_requests):
if texte[i] != '':
headers = {'Content-Type': 'application/json'}
data = {'text': texte[i]}
try:
response = requests.post(url, headers=headers, json=data)
traducere = response.json()['response']
#print(traducere)
text_final = text_final + str(traducere)
except:
print("reincercare traducere")
time.sleep(15)
try:
response = requests.post(url, headers=headers, json=data)
traducere = response.json()['response']
#print(traducere)
text_final = text_final + str(traducere)
except:
eroare_traducere = True
print("Eroare de traducere la capitolul" + str(capitol))
#print("Eroare de traducere la textul" + str(texte[i]))
time.sleep(5)
text_final = text_final + "</div>" + contents_split2[1]
if eroare_traducere == False:
with open(url_baza, 'w', encoding='utf8') as f:
f .write(text_final)
time.sleep(5)
return eroare_traducere
for i in range (0, 94):
eroare_traducere = tradu_capitol(i)
if eroare_traducere == False:
print('finalizat ' + str(i))
time.sleep(15)
print('final') Dacă ne uităm la cod vom vedea că ne propunem să prelucrăm fișiere locale care au același nume cu un ID al capitolului din carte. Codul conține o funcție care face prelucrarea capitolului care este rulată pentru toate secțiunile din carte.
În prima parte codul extrage conținutul important pentru noi, conținut care este cuprins între două tag-uri <div>. Acest conținut are un titlu <h2> și mai multe paragrafe <p>.
Am ales să împărțim acest conținut în bucăți de 50 de paragrafe. Așa cum am spus, dacă o bucată are o eroare de traducere este mai ieftin să încercăm din nou traducerea doar pentru bucata respectivă decât pentru tot textul.
Așadar, codul apelează webhookul N8N, iar dacă primește un răspuns de eroare reîncearcă traducerea, iar dacă nu concatenează răspunsul la textul final tradus.
Dacă totul funcționează corect, la sfârșit textul tradus este suprascris în HTML-ul înițial.
2.4. Traducerea textului prin N8N și Gemini 1.5 Flash 8B
Folosirea nodurilor N8N simplifică extraordinar de mult automatizarea proceselor sau integrarea diferitelor tooluri în aplicații.
Design-ul este simplu și intuitiv:
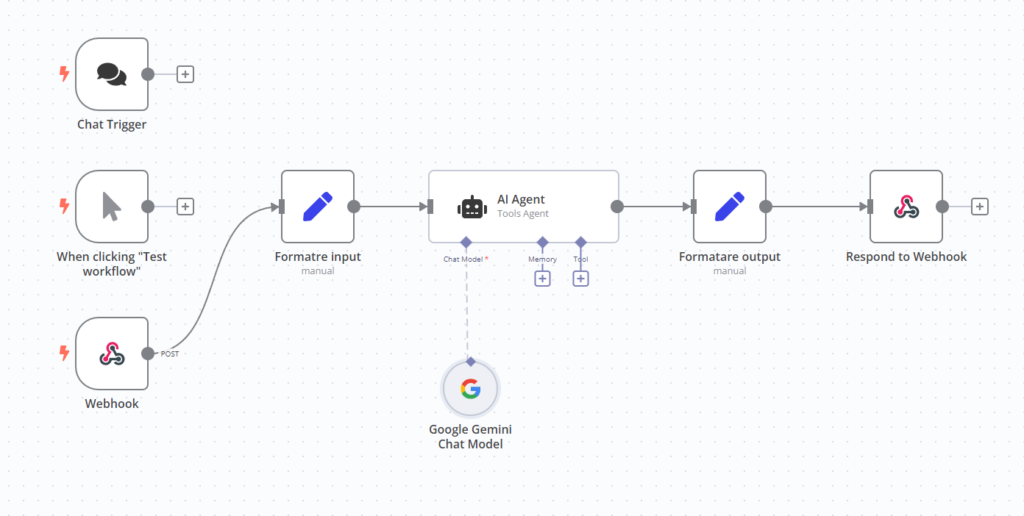
Vom folosi un webhook care creează un endpoint apelat de codul nostru python, care va răspunde cu textul prelucrat.
Avem de asemenea două noduri care setează valorile de input și output, respectiv textul care trebuie tradus și textul care este tradus.
Toată partea interesantă are loc în nodul AI care folosește modelul Gemini 1.5 Flash 8B. Instrucțiunile primite de Gemini 1.5 Flash 8B sunt simple:
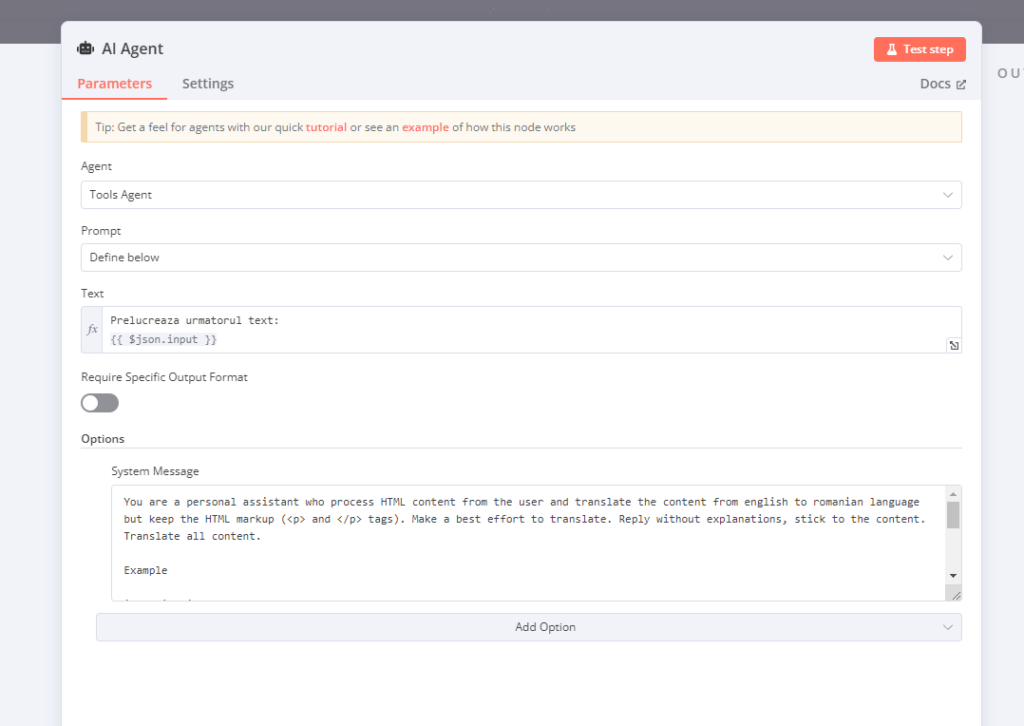
Am folosit următorul prompt:
You are a personal assistant who process HTML content from the user and translate the content from english to romanian language but keep the HTML markup (<p> and </p> tags). Make a best effort to translate. Reply without explanations, stick to the content. Translate all content.
Example
input is like:
<p>
“Every one likes his own uniform best, my lord.”
</p>
output should be like
<p>
“Toată lumea își iubește cel mai mult uniforma, domnul meu.”
</p>Pentru a ajuta modelul să înțeleagă cum dorim să răspundă am pregătit și un exemplu din care Gemini 1.5 Flash 8B își va da seama că dorim traducerea textului, dar și păstrarea codării HTML.
Atât a fost tot!
Gemini 1.5 Flash 8B primește bucățile de cod HTML, face traducerea și returnează textul procesat fără absolut nici un fel de probleme!
2.5. Asamblarea finală a cărții
În final avem structura inițială a cărții în formatul epub și noile fișiere cu textul tradus în limba română.
Putem folosi extensiile Calibre pentru a importa toate aceste fișiere într-o carte nouă pe care o putem salva cu orice nume dorim.
2.6. Observații personale
Tot procesul de traducere a cârții a durat câteva minute. Probabil scrierea codului de otimizare a citirii secvențiale a conținutului în limba engleză a durat cel mai mult timp.
Traducerea a decurs fără probleme și calitatea este deosebit de bună.
Este remarcabil faptul că deși textul original era în franceză, iar cartea în limba engleză și cu toate că limbajul cărții este cel al literaturii clasice franceze din secolul al XIX-lea, Gemini 1.5 Flash 8B a reușit să păstreze în traducere toate elementele importante. Un exemplu de paragraf tradus este următorul:
Conversația tânărului conte era foarte interesantă pentru Raoul, astfel că l-a ascultat în timp ce contelui îi plăcea să vorbească mult și cu multă plăcere. Crescut la Paris, unde Raoul a fost doar o dată; la curte, pe care Raoul n-o văzuse niciodată; farsele lui ca paj; două dueluri, pe care le-a câștigat deja, în ciuda decretelor împotriva lor și, mai ales, în ciuda supravegherii tutorului său—toate acestea au stârnit cea mai mare curiozitate în Raoul. Raoul fusese doar la casa lui M. Scarron; i-a numit lui Guiche oamenii pe care îi văzuse acolo. Guiche îi cunoștea pe toți—doamna de Neuillan, Mademoiselle d’Aubigne, Mademoiselle de Scudery, Mademoiselle Paulet, doamna de Chevreuse. El i-a criticat pe toți cu umor. Raoul tremura, ca să nu râdă alături de ceilalți la doamna de Chevreuse, pentru care nutrea o simpatie profundă și sinceră, dar fie instinctiv, fie din afecțiune pentru ducesă, el a spus tot ce a putut în favoarea ei. Laudele lui au mărit prietenia acesteia. Apoi a venit vorba de galanterie și aventuri amoroase. Și sub acest capitol, Bragelonne a avut mult mai mult de auzit decât de spus. A ascultat cu atenție și a crezut că a descoperit prin trei sau patru aventuri destul de frivole, că contelui, ca și lui, ascundea un secret în adâncul inimii sale.3. Concluzii
Gemini 1.5 Flash 8B poate fi integrat foarte ușor în diferite aplicații, atât personale, cât și de business.
N8N facilitează integrarea, dar modelul Gemini 1.5 Flash 8B este cel care pune aplicația în mișcare și o face foarte bine. Desigur pentru aplicații mai pretențioase Google ne oferă și alte variante:
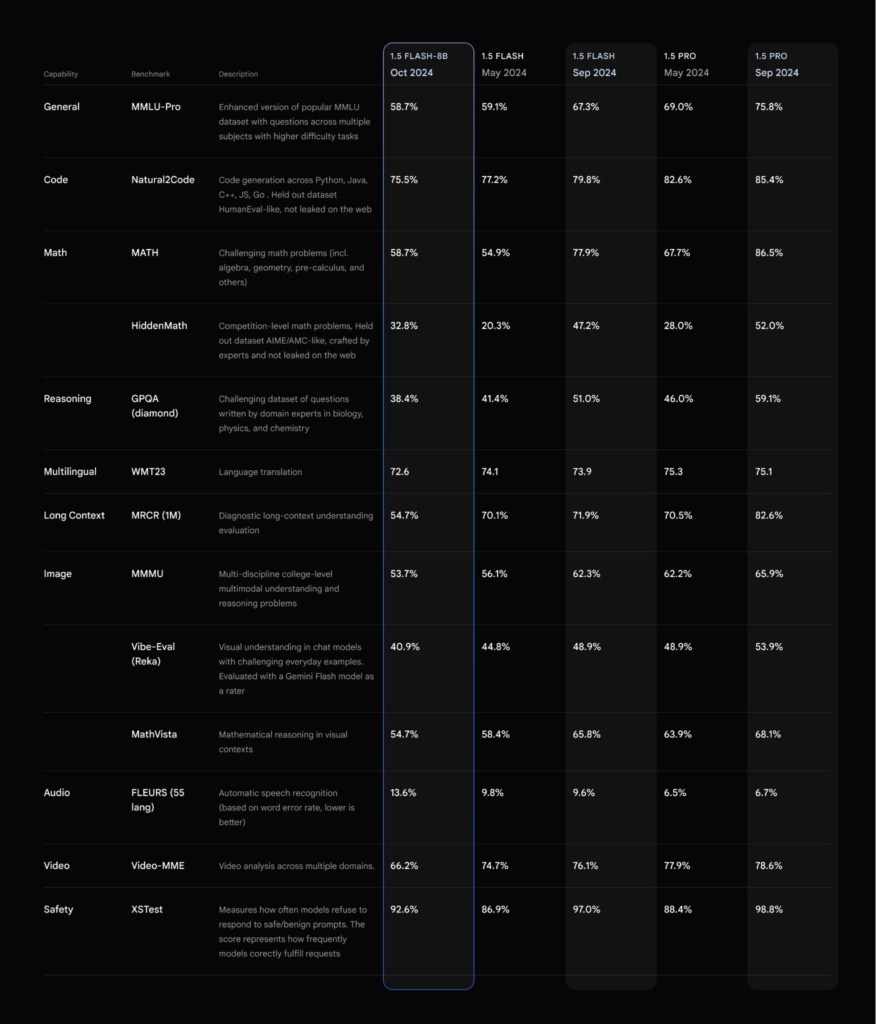
Iar dacă la toate acestea adăugăm prețul, devine aproape imbatabil, doar aproximativ 0.19 dolari pentru procesări sub 128K tokeni: