

Pe măsură ce modelele AI devin mai mari și arhitecturile mai complexe, cercetătorii și inginerii găsesc continuu noi tehnici pentru a optimiza performanța și costul general al lansării sistemelor AI în producție.
Optimizarea modelelor este o categorie de tehnici axată pe abordarea eficienței serviciului de inferență. Aceste tehnici reprezintă cele mai bune oportunități de a optimiza costurile, de a îmbunătăți experiența utilizatorului și de a crește scalabilitatea. Implementările variază de la abordări rapide și eficiente, cum ar fi cuantificarea modelului, la fluxuri de lucru în mai mulți pași, cum ar fi reducerea dimensiunii și distilarea.

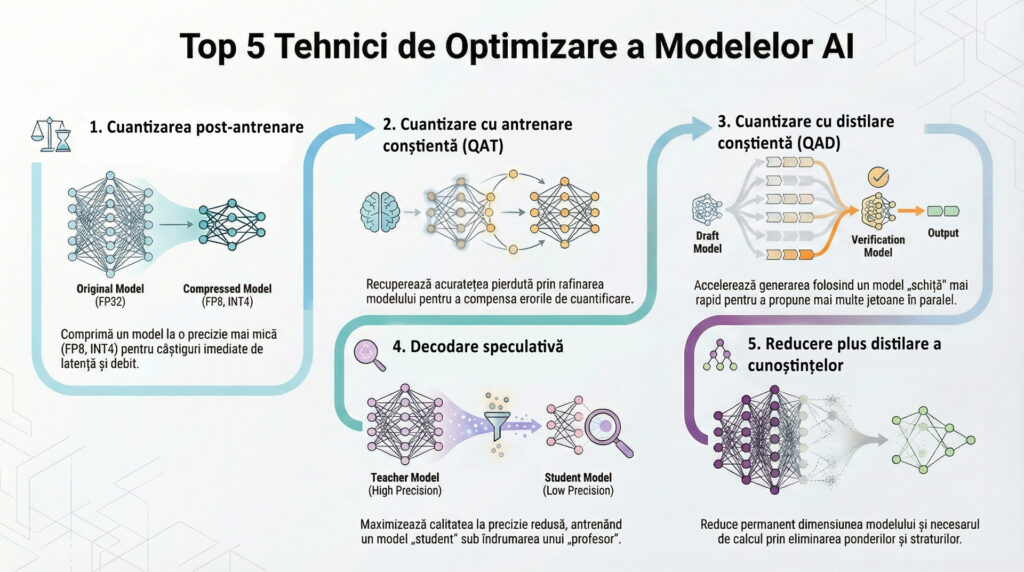
Acest articol acoperă cele mai importante cinci tehnici de optimizare a modelelor AI care folosesc NVIDIA Model Optimizer și modul în care fiecare contribuie la îmbunătățirea performanței, a TCO și a scalabilității implementărilor pe GPU-urile NVIDIA.
Tehnicile prezentate sunt cele mai puternice și scalabile pârghii disponibile în prezent în NVIDIA Model Optimizer pe care echipele le pot aplica imediat pentru a reduce costul pe token, a îmbunătăți procesarea și a accelera inferența la scară mare.
1. Cuantizarea post-antrenare
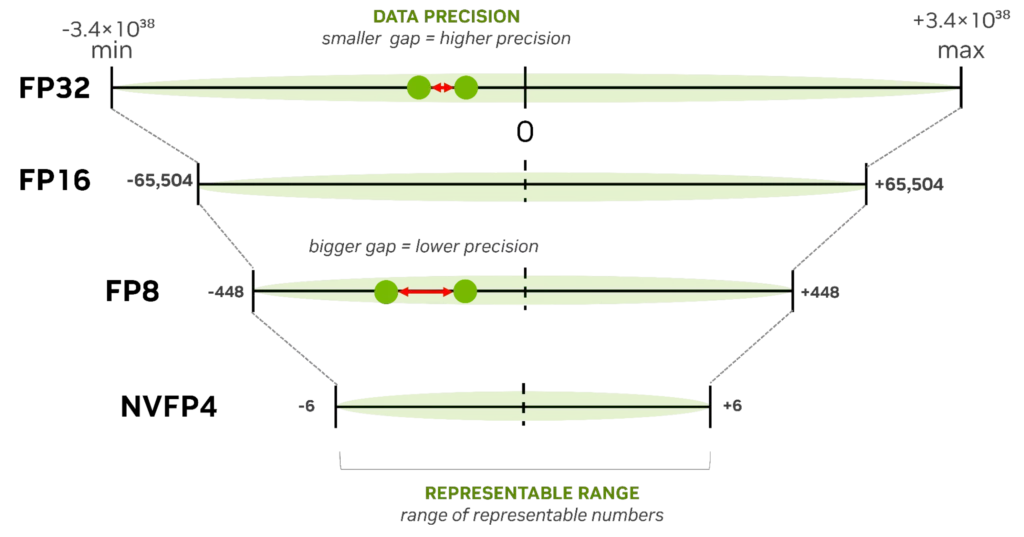
Cuantizarea post-antrenare (PTQ) este cea mai rapidă cale către optimizarea modelului AI. Puteți profita de un model existent (FP16/BF16/FP8) și îl puteți comprima într-un format de precizie mai mică (FP8, NVFP4, INT8, INT4) folosind un set de date de calibrare – fără a folosi bucla de antrenare originală. Acesta este locul unde majoritatea echipelor ar trebui să înceapă. Este ușor de aplicat cu NVIDIA Model Optimizer și oferă îmbunătățiri imediate ale latenței și ale debitului, chiar și pe modelele fundamentale masive.

| Avantaje | Dezavantaje |
| – cel mai rapid mod de implementare; – necesită un set mic de date de calibrare; – căștiguri mari de memorie, latență și putere de procesare; – posibilități mari de personalizare a cuantizării; | – necesită mai multe tehnici diferite dacă calitatea este mai scăzută decât nivelul acceptat |
2. Cuantizare cu antrenare conștientă (QAT)
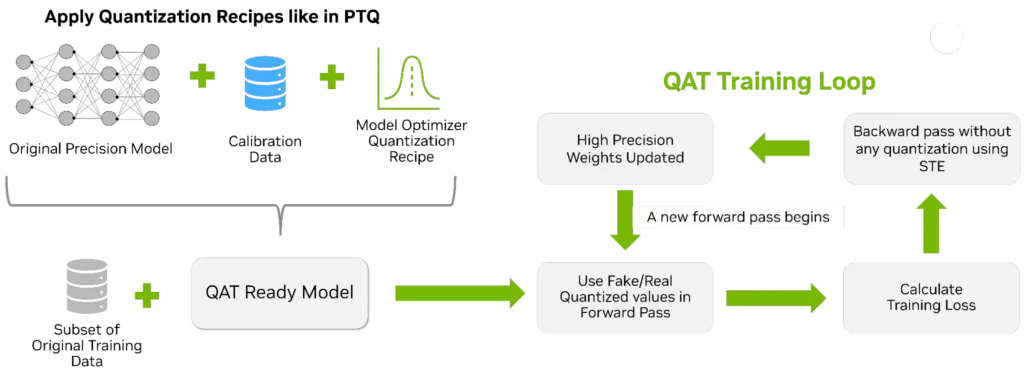
Cuantizare cu antrenare conștientă (QAT) injectează o fază scurtă, țintită de reglare fină, în care modelul este reglat pentru a ține cont de eroarea de precizie scăzută. Simulează zgomotul cuantificării în bucla directă în timp ce calculează gradienții cu o precizie mai mare. QAT este următorul pas recomandat atunci când este necesară o precizie suplimentară dincolo de ceea ce a livrat PTQ.

| Avantaje | Dezavantaje |
| – recuperarea acurateței la precizie redusă; – compatibilitate completă cu NVFP4 | – necesită date de antrenament și buget pentru pentru antrenare; – necesită mai mult timp pentru implementare decât pentru PTQ |
3. Cuantizare cu Distilare Conștientă (QAD)
Cuantizare cu Distilare Conștientă (QAD) merge cu un nivel mai departe de QAT. Cu această tehnică, modelul AI care învață ține cont de erorile de cuantificare, aliniindu-se în același timp cu modelul AI de la care învață. QAD dublează QAT prin adăugarea de elemente de predare din principiile distilării, permițând extragerea calității maximă posibilă în timp ce inferența rulează la o precizie ultra-scăzută. QAD este o opțiune eficientă pentru sarcinile ulterioare care sunt în mod notoriu afectate de degradarea semnificativă a performanței după cuantificare.
| Avantaje | Dezavantaje |
| – acuratețe ridicată; – ideală pentru scenarii cu post antrenare; | – necesită mai multe cicluri de antrenare succesive; – are nevoie de mai multă memorie; – implementare mai complexă; |
4. Decodare speculativă
Pasul de decodare în inferență este bine cunoscut pentru că suferă de blocaje algoritmice de procesare secvențială. Decodarea speculativă abordează direct acest lucru utilizând un model AI mai mic sau mai rapid (cum ar fi EAGLE-3) pentru a propune o predicție de token-uri, pe care apoi le verifică în paralel cu modelul țintă.
Acest lucru reduce latența secvențială la pași unici și reduce dramatic procesarea cantităților mari de date, fără a atinge ponderile modelului AI.

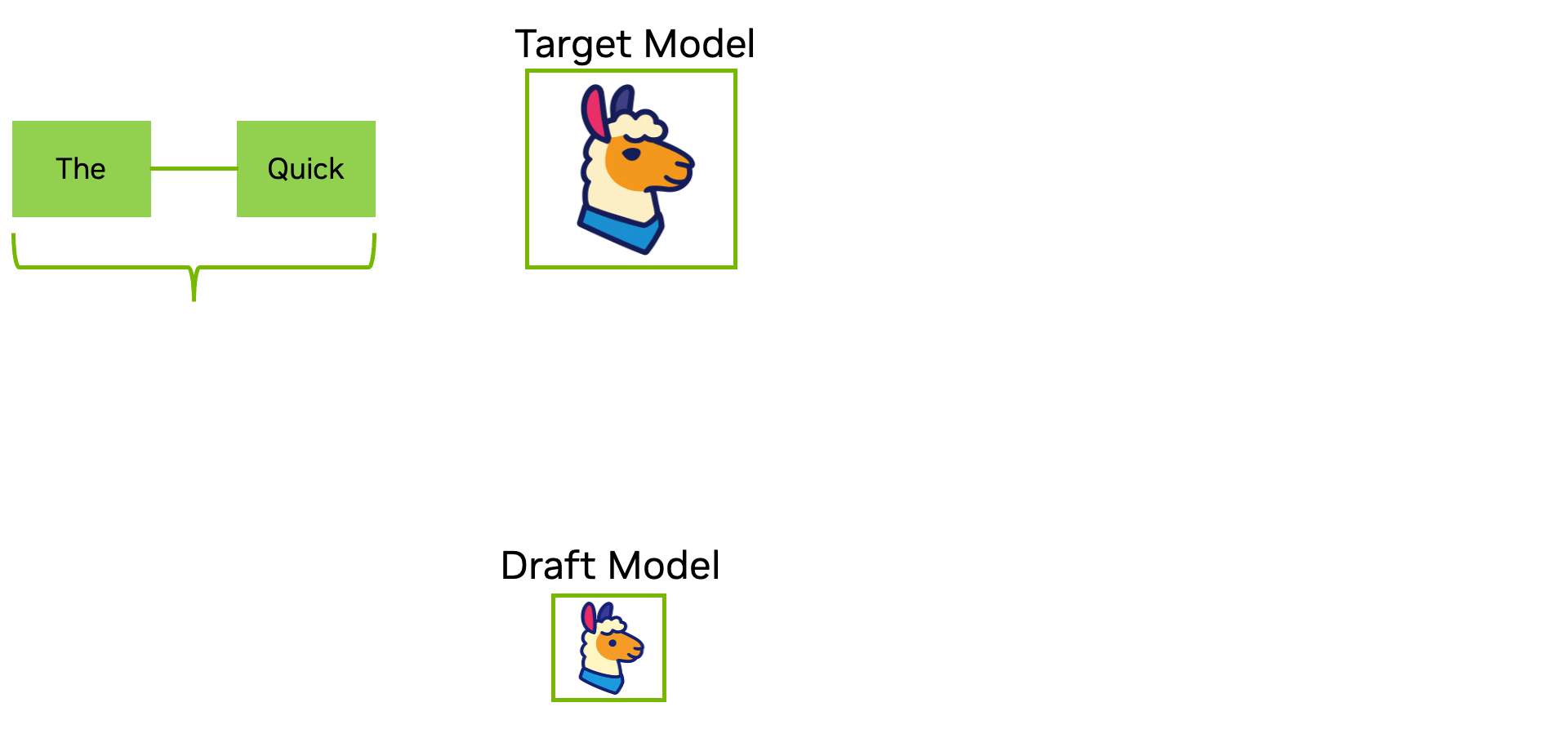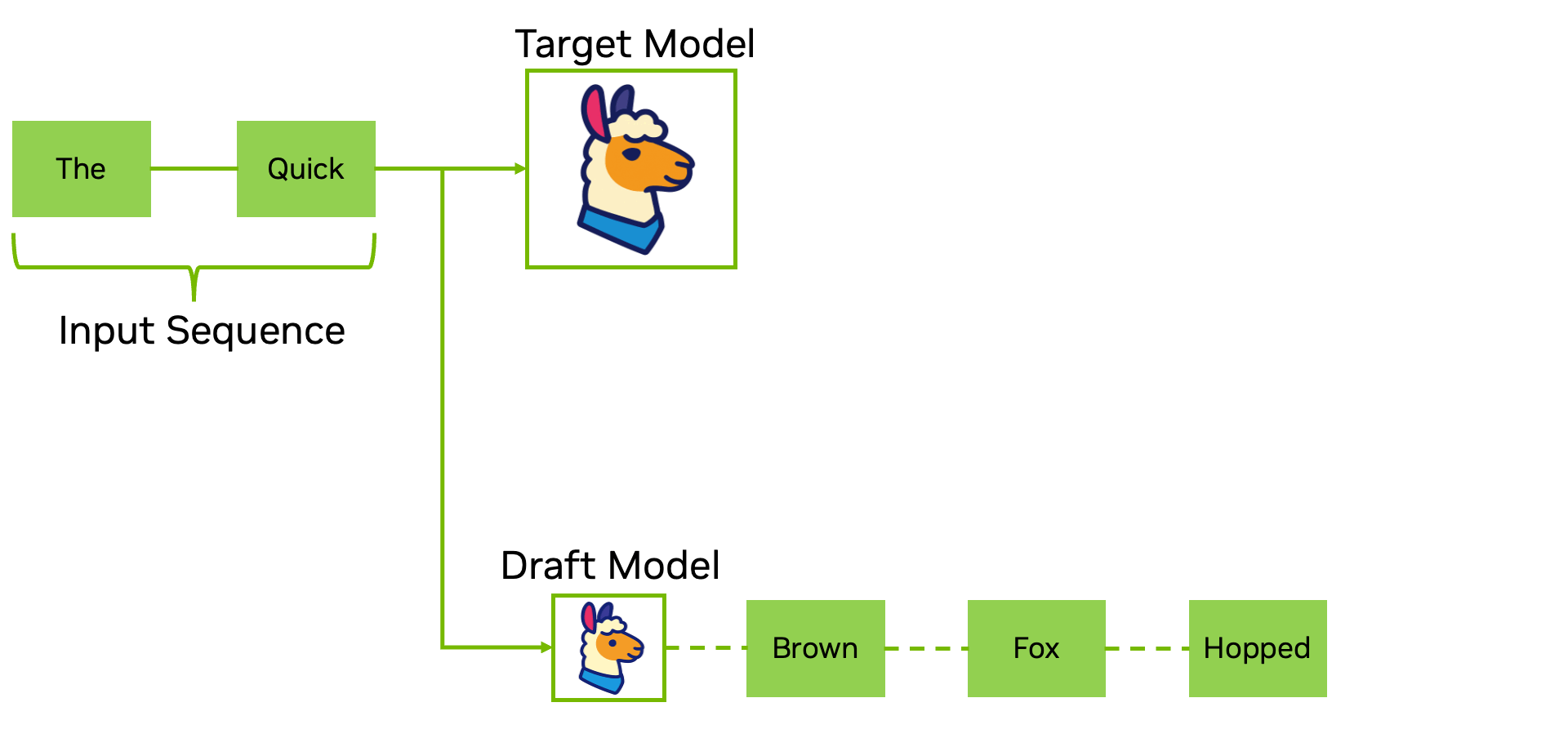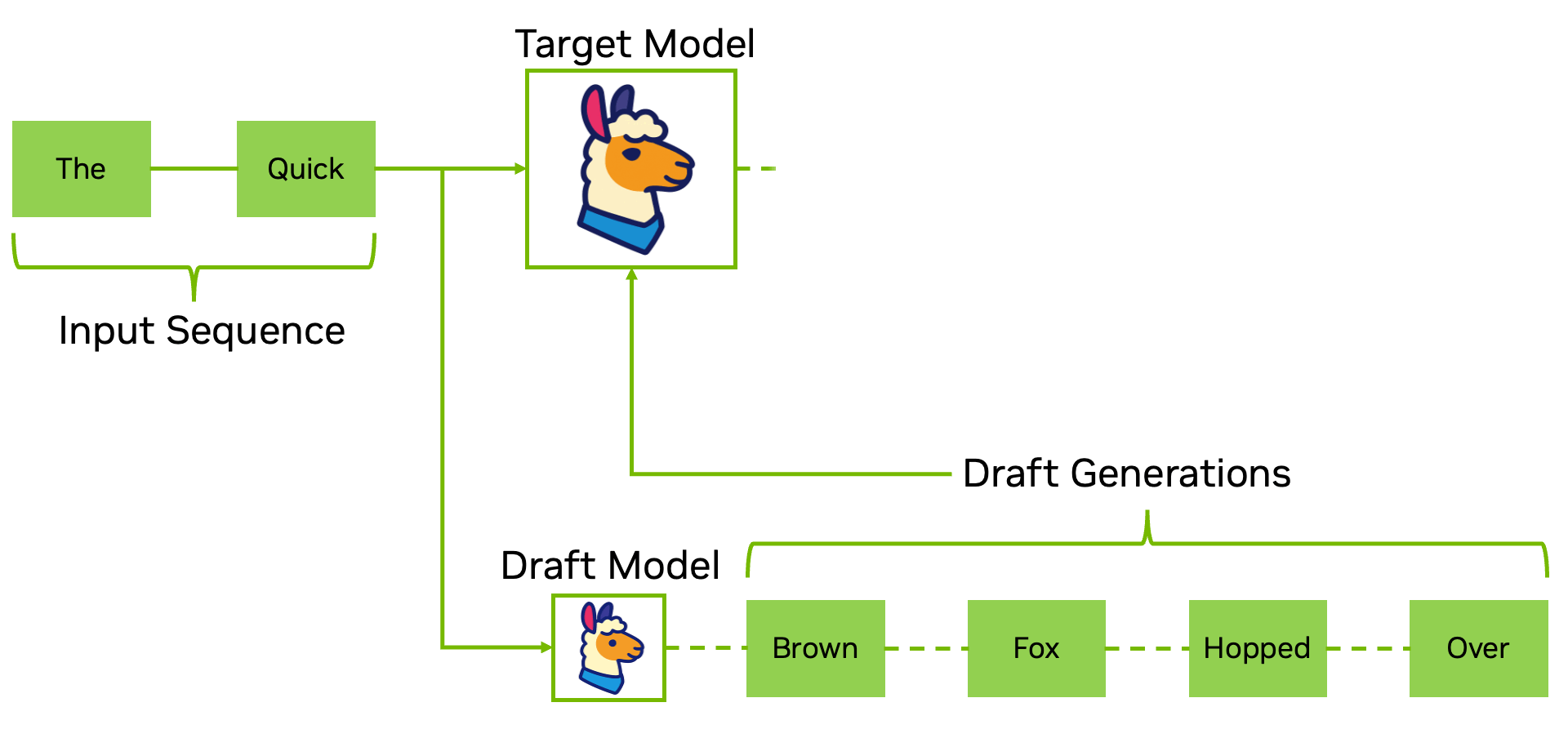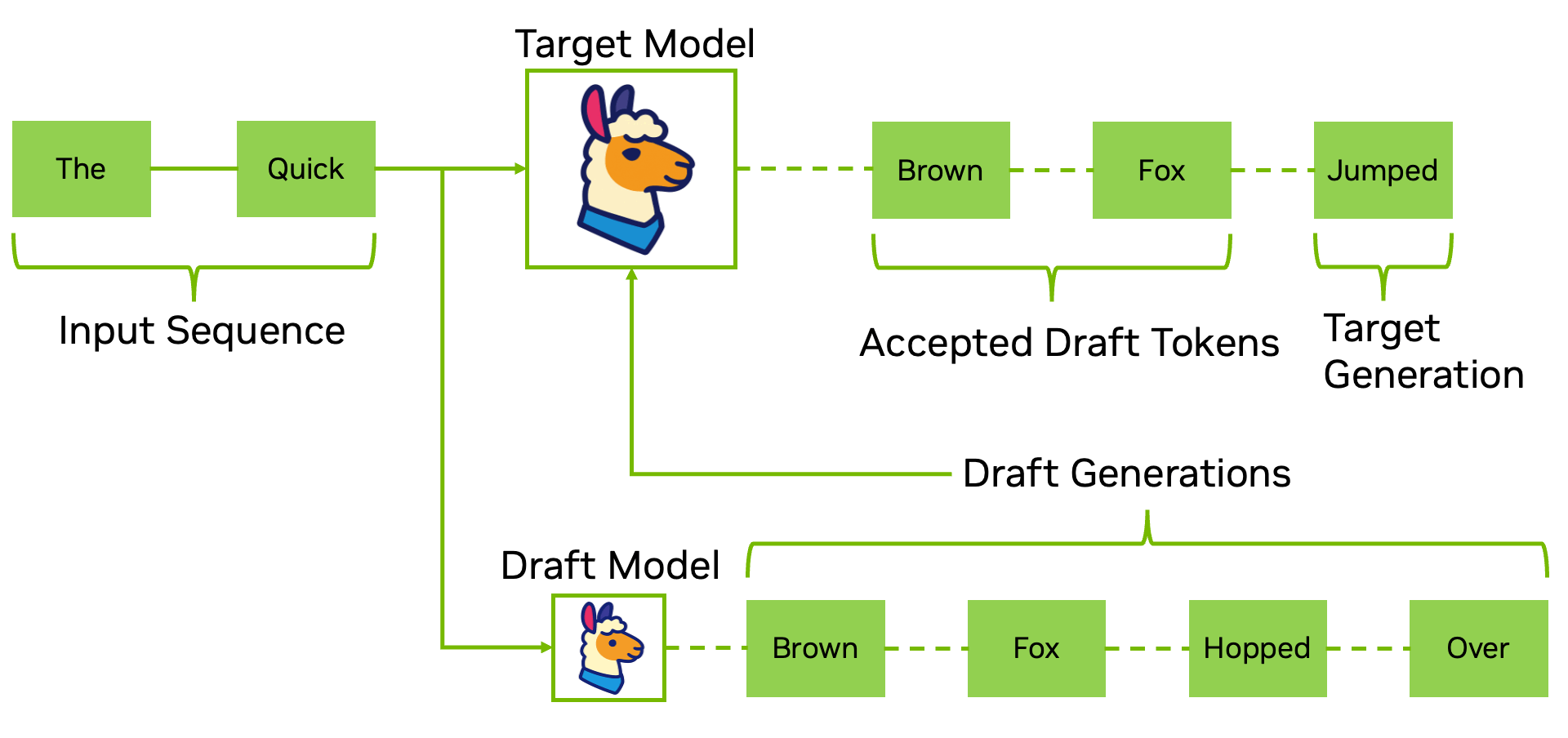
Decodarea speculativă este recomandată atunci când doriți accelerări imediate ale generării fără reantrenare sau cuantificare și se integrează bine cu celelalte optimizări din această listă pentru a compune câștigurile de debit și latență.
| Avantaje | Dezavantaje |
| – reducerea semnificativă a latenței la decodare; – funcționează perfect cu PTQ/QAT/QAD și NVPF4 | – necesită ajustări și atenție sporită; |
5. Reducere plus distilare a cunoștințelor
Reducerea dimensiunii este o cale de optimizare structurală. Această tehnică elimină ponderi, straturi și/sau capete pentru a face modelul mai mic. Distilarea apoi învață noul model AI mai mic cum să gândească ca modelul AI mai mare care l-a antrenat. Această strategie de optimizare multistep modifică permanent performanța modelului, deoarece amprenta de calcul și memorie de bază este permanent redusă.

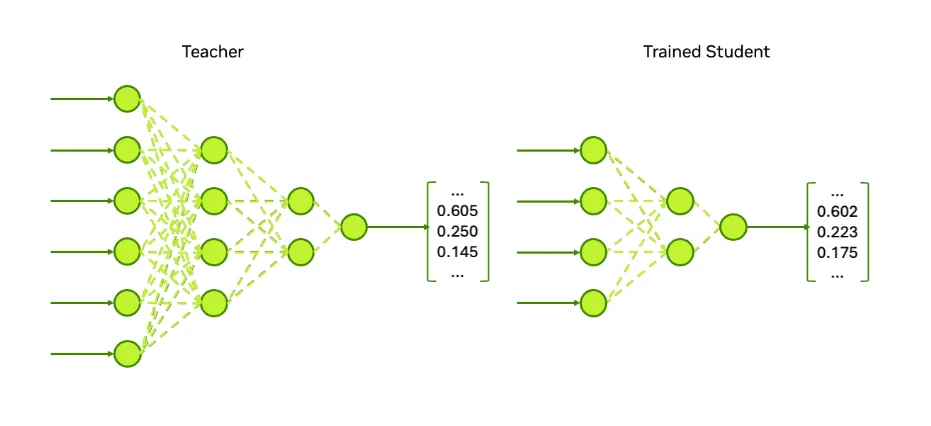
Reducerea dimensiunii plus distilarea cunoștințelor pot fi utilizate atunci când alte tehnici din această listă nu pot oferi economiile de memorie sau de calcul necesare pentru a îndeplini cerințele aplicației. Această abordare poate fi utilizată și atunci când echipele sunt deschise să facă modificări mai agresive unui model existent pentru a-l adapta pentru cazuri de utilizare ulterioare specializate specifice.
| Avantaje | Dezavantaje |
| – reducerea numărului de parametri; – modelele AI antrenate se comportă ca modelele AI mari; | – distilarea agresivă reduce acuratețea noului model AI; – este nevoie de o procesare mai intensă decât pentru PTQ |
Concluzie
Tehnicile de optimizare vin în toate formele și dimensiunile.
PTQ, QAT, QAD și reducerea dimensiunii plus distilare fac modelele AI nou antrenate intrinsec mai ieftine, mai mici și mai eficiente din punct de vedere al memoriei.
Decodarea speculativă face generarea mai rapidă prin reducerea latenței secvențiale.
Fiecare tehnică vine cu avantajele și dezavantajele ei, de aceea este important ca înainte de folosire să se facă o analiză a scopului pentru care modelul AI va fi folosit ulterior antrenării.