



Folosim și analizăm modele LLM de inteligență artificială, dar nu am discutat niciodată despre două elemente decisive: cost și durată de antrenare.
Pentru noi ca utilizatori aceste întrebări nu sunt esențiale, dar răspunsurile la ele pot face diferența între un model LLM profitabil și altul destinat eșecului.
1. Introducere
Desigur antrenarea este doar un ultim pas în procesul de creare a modelelor LLM. Pașii premergători țin de stabilirea algorimilor și identificarea seturilor de date de antrenament, identificare care de multe ori se bazează pe supervizarea umană.
În cele ce urmează vom analiza estimarea costului și duratei de dezvoltare doar din punct de vedere a necesarului de putere de procesare proporțională cu dimensiunea și volumul modelului LLM țintit.
2. Putere de procesare necesară
Dezvoltarea rapidă a inteligenței artificiale a adus în prim plan importanța hardware-ului specializat pentru antrenarea modelelor lingvistice de mari dimensiuni (LLM). Mulți timp accentul s-a pus pe dezvoltarea puterii procesoarelor, iar plăcile grafice au rămas în plan secundar fiind asociate cu divertismentul sau jocurile multimedia.
Unitățile Centrale de Procesare (CPU) sunt proiectate pentru executarea secvențială a sarcinilor complexe, având puține nuclee dar foarte puternice. În schimb, Unitățile de Procesare Grafică (GPU) conțin mii de nuclee mai simple, optimizate pentru calcule paralele – exact tipul de operații necesare în antrenarea rețelelor neurale.
Un CPU modern poate avea 8-64 de nuclee, în timp ce un GPU NVIDIA de ultimă generație poate avea peste 10.000 de nuclee CUDA. Această arhitectură paralelă face ca GPU-urile să fie de sute de ori mai eficiente în operațiile matematice necesare antrenării modelelor AI.
Unitatea de măsurare a puterii de procesare este FLOPS-ul. FLOPS (Floating Point Operations Per Second) reprezintă numărul de operații în virgulă mobilă pe care un procesor le poate executa într-o secundă. În contextul AI, vorbim de obicei despre TFLOPS (Tera FLOPS), unde: 1 TFLOPS = 1 trilion de operații în virgulă mobilă pe secundă
Pentru antrenarea modelelor lingvistice mari, capacitatea de procesare necesară se măsoară în sute sau chiar mii de TFLOPS.
Atunci când discutăm despre antrenarea modelelor AI plăcile NVIDIA sunt partea esențială a echipamentelor tehnice utilizate. Spre exemplu se pot utiliza plăci grafice cu specificații extraordinare precum:
NVIDIA H100 (Hopper)
- 80 GB memorie HBM3
- Până la 4.000 TFLOPS (FP8)
- 80 GB memorie HBM3
- Consum energetic: 700W
- Preț aproximativ: 30.000 EUR
NVIDIA A100
- 80 GB memorie HBM2e
- Până la 312 TFLOPS (FP16)
- Consum energetic: 400W
- Preț aproximativ: 10.000-15.000 EUR
NVIDIA A6000
- 48 GB memorie GDDR6
- 309.7 TFLOPS (FP16)
- Consum energetic: 300W
- Preț aproximativ: 4.000-5.000 EUR

În practică, antrenarea modelelor mari necesită mai multe GPU-uri conectate în paralel care folosesc tehnologii precum:
- NVLink pentru comunicare inter-GPU;
- InfiniBand pentru comunicare între nodurile de calcul;
- CUDA pentru programare paralelă.
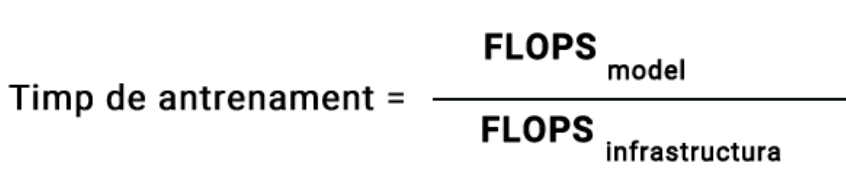
Așadar putem stabili o formulă de calcul al timpului necesar pentru antrenarea unui model LLM ca fiind puterea de calcul necesară împărțită la puterea de calcul disponibilă pentru antrenament
Formula finală este destul de simplă:

2. Estimarea puterii necesare pentru antrenarea modelului LLM
Vom începe cu calcularea numărului de operațiuni necesare pentru procesarea datelor prin Transformer folosind studiul de cercetare „Empirical Scaling Laws for Language Model Performance” care explorează relațiile empirice dintre performanța modelului de limbaj și factorii specifici ai modelului LLM, dimensiunea datasetului și puterea de calcul utilizată pentru antrenare.
Această cercetarea se concentrează pe studierea performanței modelului de limbaj bazat pe arhitectura Transformer, folosind datele din setul de date WebText2. Performanța modelului LLM se măsoară prin eroarea de entropie cruză (cross-entropy loss).
Rezultate empirice și legi de putere
- Performanța modelului urmează legi de putere precise în funcție de dimensiunea modelului (N), dimensiunea datasetului (D) și puterea de calcul utilizată (C), cu tendințe care se extind pe mai mult de șapte ordine de mărime.
- Alți parametri arhitecturali, cum ar fi lățimea sau adâncimea rețelei, au efecte minime asupra performanței în limite rezonabile1.
Dependența de scară
- Performanța depinde puternic de scară, care include numărul de parametri ai modelului (N), dimensiunea datasetului (d), numărul de tokeni (ctx) și puterea de calcul (C). Performanța se îmbunătățește atunci când se măresc toți acești factori în tandem.
Pe baza studiului putem folosi următoarea formulă de calcul a puterii necesare prelucrării datelor / token:


Factorul 2 provine de operațiile artimetice utilizate la procesarea matricială a informației (utilizarea vectorilor/tokenilor).
Ținând cont de propagarea inversă și calcularea gradienților în timpul antrenamentului putem aproxima numărul de operații final per token ca fiind:


Pentru a rezuma, necesarul de FLOPS pentru antrenarea modelul de dimensiunea N poate fi estimat prin formula:

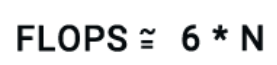
3. Calcularea FLOPSurilror infrastructurii de antrenament
Fiecare model de GPU (cum ar fi H100, A100 sau V100 de la Nvidia) are propria sa performanță FLOPS, care variază în funcție de tipul de date (factor de formă) utilizat. De exemplu, operațiunile cu FP64 sunt mai lente decât cele cu FP32 și așa mai departe. FLOPS-ul teoretic de vârf pentru un anumit GPU poate fi găsit de obicei pe pagina de specificații a produsului.
Cu toate acestea, FLOPS-ul maxim teoretic pentru un GPU este adesea mai puțin relevant în practică atunci când se antrenează modele de limbaj mari. Acest lucru se datorează faptului că aceste modele sunt de obicei antrenate pe mii de GPU-uri interconectate, unde eficiența comunicării în rețea devine crucială. Dacă comunicarea între dispozitive devine un blocaj, aceasta poate reduce drastic viteza totală, făcând FLOPS-ul real al sistemului mult mai mic decât se aștepta.
Pentru a rezolva acest lucru, vom folosi o măsurătoare numită utilizare a modelului FLOPS (MFU) – raportul dintre debitul observat și debitul maxim teoretic, presupunând că hardware-ul funcționează la eficiență maximă, fără memorie sau suprasarcină de comunicare. În practică, pe măsură ce numărul de GPU-uri implicate în antrenament crește, MFU tinde să scadă. Atingerea unui MFU de peste 50% este o provocare cu configurațiile actuale.
În lucrarea de cercetare „Efficient Training of Large Language Models via Gradient-Based Meta-Learning” au fost studiate diferite metode pentru a reduce complexitatea și costul antrenării modelelor de limbaj mari, care sunt esențiale pentru aplicațiile moderne de inteligență artificială.
Autorii au propus o metodă de învățare META bazată pe gradient, care permite modelului LLM să adapteze rapid parametrii săi la noi sarcini sau date, reducând semnificativ timpul și resursele necesare pentru antrenare.
Pentru acest timp de algorim s-a calculat un MFU de 38%, sau 380 teraflopi de debit per GPU, atunci când sunt folosite pentru antrenament nu mai puțin de 16 000 unități GPU.


Pentru a rezuma, atunci când calculăm necesarul puterii de calcul a infrastructurii pentru antrenamentul unui model LLM trebuie urmați acești pași:
- se identifică maximul FLOPS teoretic pentru GPU-ul ales;
- se estimează MFU-ul pe baza numărului de GPU-uri folosit în structura rețelei utilizate (folosind diferite teste concrete);
- se calculează valoarea totală a FLOPS teoretică utilizănd MFU-ul și numărul de FLOPS de la primul pas;
- se înmulțește rezultatul cu numărul de GPU-uri alese pentru antrenament.
4. Studiu de caz: calcule pentru antrenarea modelului Llama 3 405B
Pentru că pănă acum am făcut mai mult teorie e timpul să trecem la niște estimări mai practice și am ales modelul Llama 3 405B – unul dintre cele mai avansate modele AI din acest moment, furnizat de Meta.
Llama 3.1 405B a fost antrenat pe un set imens de 15.6 trilioane de tokeni.

Pentru a calcula costurile asociate dezvoltării acestui model începem cu calcularea FLOPS-urilor necesare pentru antrenament:


O putere de calcul imensă care va trebui distribuită evident pe o rețea multi GPU dacă dorim să obținem rezultate pe perioada vieții noastre.
Meta este o companie care nu se uită la cheltuieli, așa că a ales să folosească 16 000 de GPU-uri de tip H100.
Debitul mediu rezultat a fost de 400 de teraflopi per GPU.
Aceasta înseamnă că infrastructura de instruire poate oferi un randament total de:

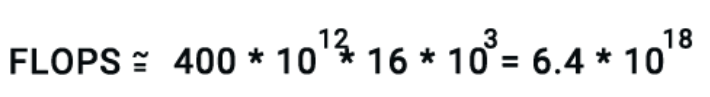
În cele din urmă, împărțind FLOP-urile totale necesare la debitul disponibil și convertind rezultatul în zile (deoarece ceea ce ne pasă cu adevărat este numărul de zile de antrenament), obținem aproximativ 70 de zile.
Acum putem calcula costul total necesare pentru a antrena un model de o astfel de dimensiune înmulțind costul pe oră GPU cu orele calculate pentru antrenament.
De exemplu, dacă un GPU H100 costă aproximativ 2 USD pe oră, costul total pentru antrenarea acestui model ar fi de aproximativ 52 milioane de dolari!
5. Concluzii
Este evident că antrenarea unui model AI avansat nu este un lucru ușor și nici ieftin. Planificarea defectuoasă a unei structuri de GPU-uri pentru antrenament poate duce la pierderea datelor sau chiar la cheltuieli nejustificate.
Tehnicile de antrenament afectează de asemenea rezultatele estimate.
Atunci când are loc antrenarea modelelor AI nu mai vorbim de sute de GPU-uri, ci de clustere de sute de mii (recent xAi a lui Elon Musk a anunțat că va construi un cluster cu 200 000 de GPU-uri NVIDIA). Sunt costuri imense care vin și cu așteptări mari.
Cred că soluția reală este trecerea la dezvoltarea unor modele SML (precum Llama 3.2 8B, Qwen2.5 14B etc) mai mici, mai specializate, capabile de înțelegerea instrucțiunilor umane și totodată capabile să lucreze în comun pentru îndeplinirea unor sarcini complexe.