



NVIDIA a anunțat lansarea modelului LLAMA-Minitron 3.1 4B care are la baza modelul LLAMA 3.1. 8B
Noul model este mai mic și permite rularea cu rapiditate și de pe dispozitive mai puțin puternice.
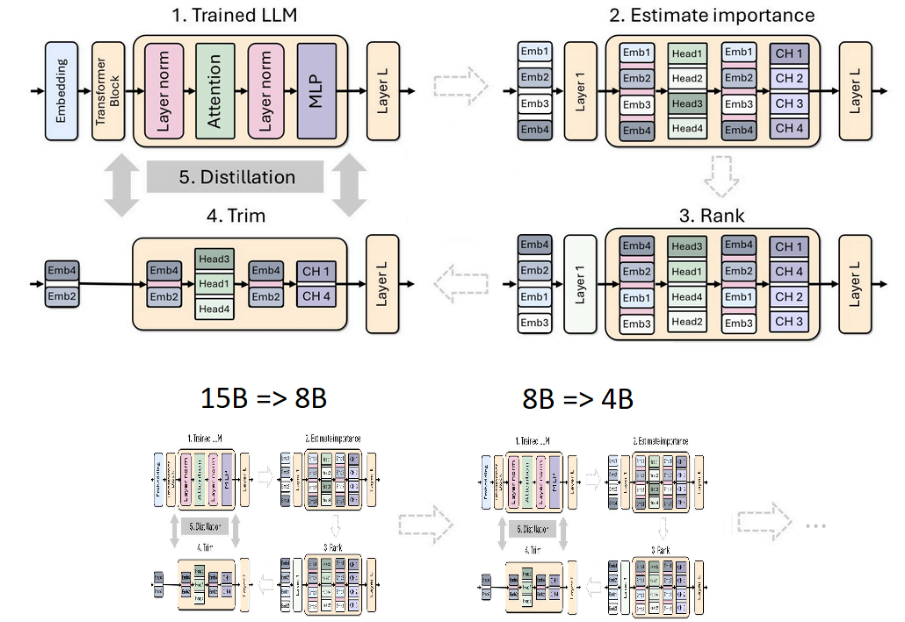
Pentru a creea noul model, NVIDIA a folosit noi tehnici de cuantizare și de structurare a informațiilor.
Așa numita tehnică de „fasonare” („pruning”) a datelor permite eliminarea informațiilor mai puțin importante pentru a reduce dimensiunea modelului LLM, dar în același timp păstrând constantă performanța. În cazul modelului Minitron 3.1.4B, s-au eliminat 16 straturi neuronale.
Pe lângă fasonare, NVIDIA a aplicat și o distilare a modelului. Această tehnică face ca noul model să fie antrenat să copieze comportamentul unui model mai mare și mai complex.
Desigur LLAMA Minitron 3.1.4B are performanțe mai scâzute decât modelul origininal, dar acestea sunt compensate printr-o rapiditate sporită.

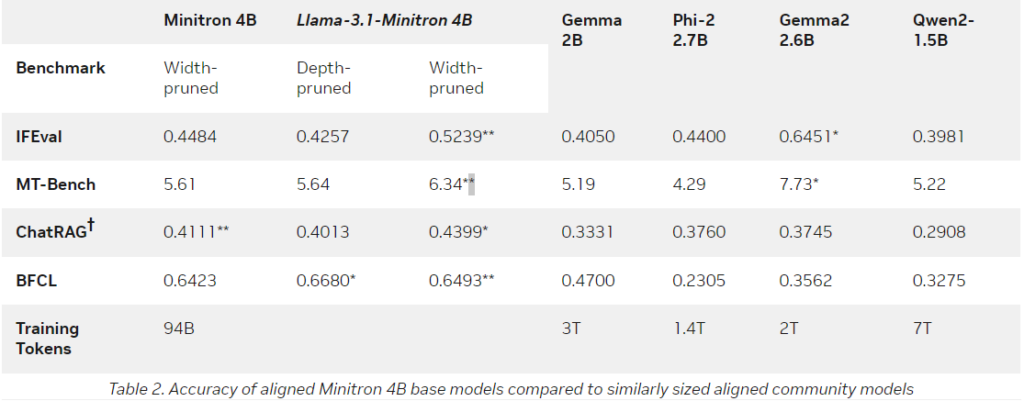
În testele de performanță, LLAMA-3.1 -Minitron 4B a depășit multe modele mici consacrate precum Phi-2 2.7B, Gemma2 2.6B sau Qwen2-1.5B.

Llama 3.1. Minitron 4B Q8 are o dimensiune de aproximativ 4.8 FB și folosește resursele în mod eficient putând fi folosit în locuri în care utilizarea unui LLM mare ar fi ineficientă.