



În era digitală actuală, imaginile generate de AI: au devenit un domeniu fascinant și în continuă evoluție. Trei modele extraordinare – Flux 1.1, Stable Diffusion 3.5 Large și Janus 1 .3B au atras atenția comunității tech prin capacitățile lor remarcabile. Să explorăm în detaliu cum funcționează aceste sisteme și ce le face unice.
1. Cum funcționează imaginile generate de AI?
Înainte de a analiza modelele specifice, este esențial să înțelegem procesul fundamental prin care AI-ul generează imagini.
În articolele precedente am analizat comportamentul modelelor generative de tip text, precum Llama 3.2 sau Qwen 2.5. Deși poate ne imaginăm că și modelele generative vizuale funcționează la fel, totuși sunt câteva diferențe semnificative.
Imaginile generate de AI au la bază de obicei așa numitele modele de tip diffusion.

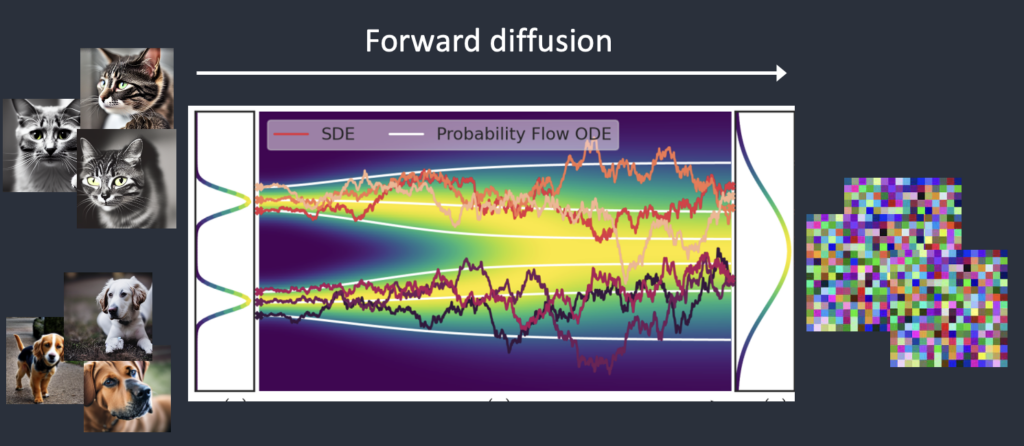
Aceste modele folosesc așa numita difuzie directă și difuzie inversată.
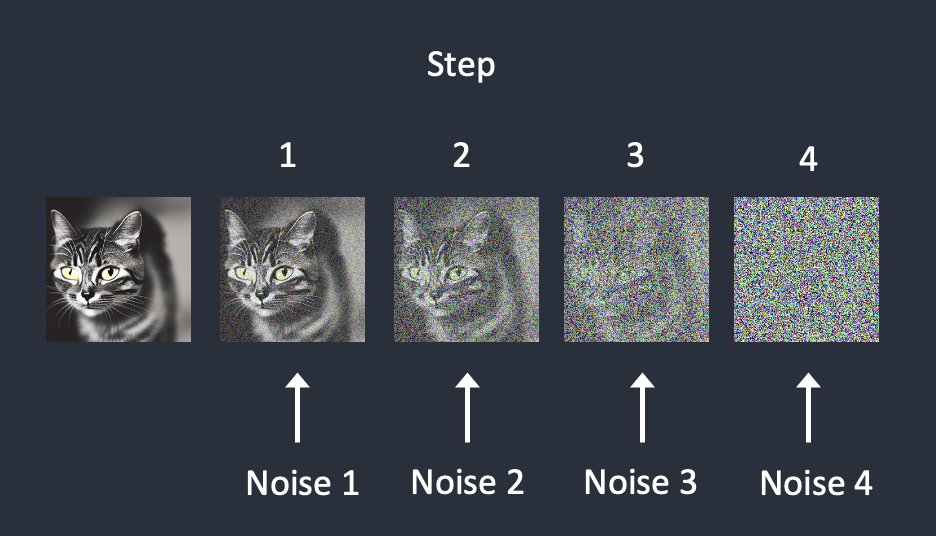
În prima fază – în difuzia directă, modelul întroduce zgomot peste o imagine cu care se antrenează transformând-o încet într-o formă din care nu se mai distinge nimic (similar cu adăugarea unui strop de cerneală într-un pahar cu apă, cerneală care se amestecă în timp cu apa din pahar).


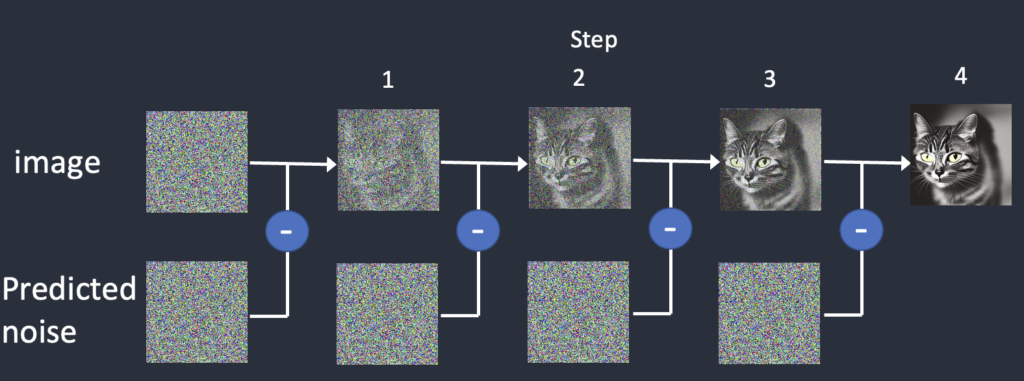
În pasul doi, al difuziei indirecte modelul încearcă să refacă imaginea pornind de un zgomot absolut.
Modelul se antrenează adăugând zgomot imaginilor în mai mulți pași, iar apoi încearcă să prezică cât de mult zgomot a fost adăugat pentru a permite refacerea imagininii inițiale.


Modelele AI de aces tip implică și alți pași cheie:
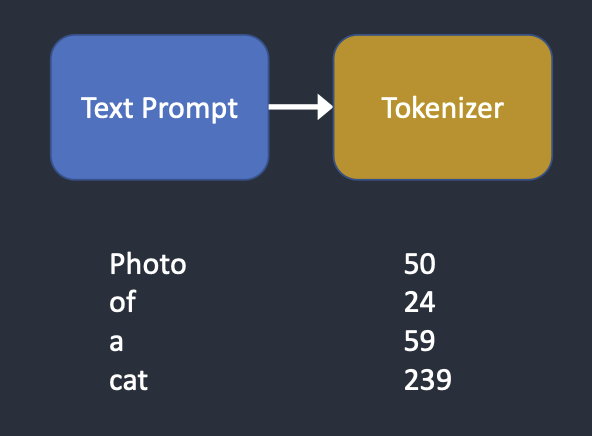
Encodarea Textului
- Sistemul primește o descriere textuală (prompt);
- Textul este transformat în vectori numerici care reprezintă conceptele și atributele dorite.

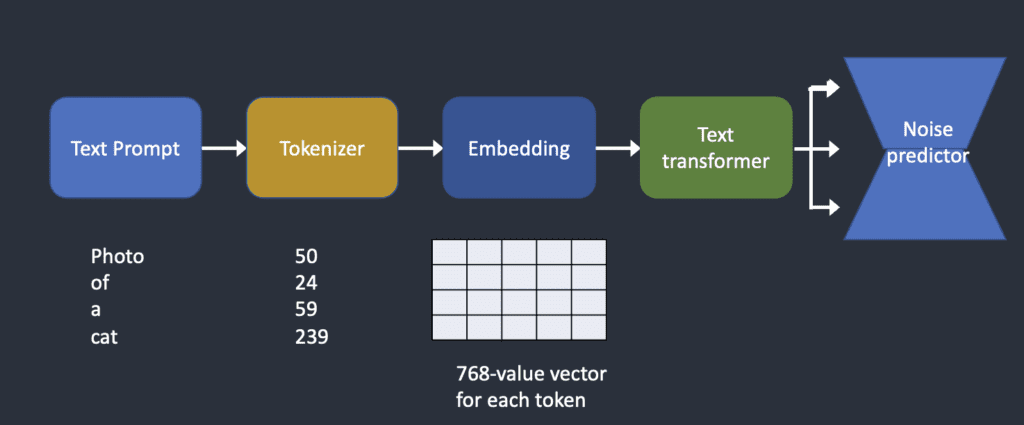

Procesul de prezicere a zgomotului

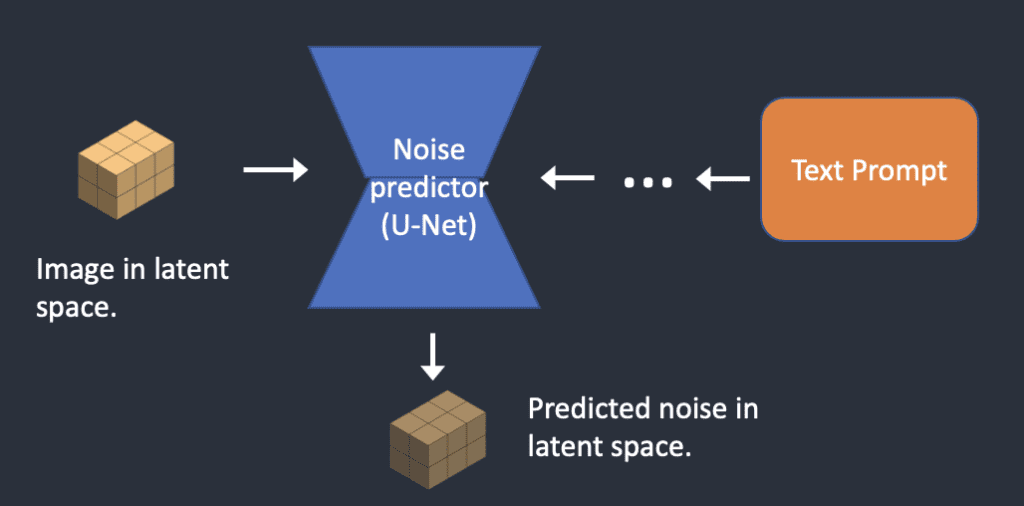
- Începe cu zgomot aleatoriu;
- Prin iterații succesive, zgomotul este transformat treptat într-o imagine;
- Modelul învață să „curețe” zgomotul folosind informațiile din prompt.
Rafinarea Imaginii
- Detaliile fine sunt adăugate progresiv;
- Consistența și coerența imaginii sunt îmbunătățite;
- Se aplică corecții pentru aspecte precum proporțiile și perspectiva.


2. Flux 1.1: o adevărată revoluție pentru imaginile generate de AI
Flux 1.1 reprezintă un salt important în domeniul generării de imagini AI, aducând mai multe inovații semnificative.
Modelul poate fi folosit prin platforma Replicate, HuggingFace sau direct și gratuit pe calculatorul personal.
Flux 1.1 folosește o arhitectură neurologică avansată care permite o mai bună înțelegere a contextului și instrucțiunilor date de utilizator. Un promp mai bun duce automat la îmbunătățirea detaliilor fine și texturilor și senzației de realism.
Pe lângă aceste puncte tari, Flux 1.1 aduce și un sistem superior de înțelegere a relațiilor spațiale între elemente unei imagini, precum și a fizicii care stă în spatele obiectelor, contribuind și mai mult la generarea unor scene plauzibile.
Flux 1.1 se remarcă printr-o calitate excepțională a detaliilor de prim plan, în special a generării personajelor umane, precum și prin păstrarea consistenței atunci când este nevoie de generarea unor scene complexe.
Flux 1.1 vine cu unul din cei mai buni timpi de generare a imaginilor prin modele AI de pe piață
3. Stable Diffusion 3.5 Large: perfecționarea unei tehnologii uluitoare
Stable Diffusion este un alt model de inteligență artificială care poate genera imagini din text. Este unul dintre cele mai populare instrumente AI pentru crearea de artă digitală.
La baza sa, Stable Diffusion este un model de difuzie latentă. În loc să lucreze direct cu imaginile în dimensiunea lor completă, sistemul comprimă mai întâi imaginea într-un spațiu latent mult mai mic, reducând astfel dramatic timpul și resursele necesare pentru procesare.
Procesul poate fi împărțit în câțiva pași cheie:
Comprimarea în spațiul latent
- Imaginile sunt mai întâi comprimate într-un spațiu latent folosind un „autoencoder variațional” (VAE);
- Acest spațiu este de 48 de ori mai mic decât imaginea originală;
- Pentru o imagine de 512×512 pixeli, reprezentarea latentă este de doar 64×64.
Procesarea textului
- Textul introdus (prompt-ul) este împărțit în tokens folosind tokenizer-ul CLIP;
- Fiecare token este convertit într-un vector de embedding de 768 valori;
- Aceste embeddings sunt procesate de un transformer pentru a ghida generarea.
Procesul de difuzie
- Se începe cu zgomot aleator în spațiul latent;
- Un model U-Net prezice zgomotul din reprezentarea latentă;
- Zgomotul este eliminat treptat în mai mulți pași;
- Textul ghidează acest proces prin mecanismul de „cross-attention”.
Decodificarea finală
- După eliminarea zgomotului, reprezentarea latentă este decodificată înapoi într-o imagine;
- VAE-ul recreează detaliile fine ale imaginii.
Un aspect important este parametrul CFG (Classifier-Free Guidance), care controlează cât de strict urmează modelul prompt-ul text. O valoare mai mare înseamnă că imaginea va urma mai fidel descrierea, dar poate produce rezultate mai puțin naturale.
Stable Diffusion 3.5 Large poate fi folosit prin platforma Replicate, HuggingFace sau descărcat direct pe calculator.
Stable Diffusion poate funcționa în mai multe moduri:
- Text-to-image: generează imagini din descrieri text;
- Image-to-image: modifică imagini existente folosind text;
- Inpainting: modifică doar părți specifice ale unei imagini;
- Depth-to-image: generează imagini noi păstrând structura 3D.
Stable Diffusion 3.5 Large aduce îmbunătățiri semnificative față de versiunile anterioare, printr-o îmbunătățire a scalabilității arhitecturii, o procesare mai eficientă a prompturilor complexe și mai ales un sistem mai avansat de control al stitlului și compoziției scenelor generate.
3. Janus 1.3B: o nouă perspectivă în generarea de imagini
Al treilea model AI prin care se pot genera imagini despre care vorbim în acest articol este Janus 1.3B care se bazează pe o arhitectură de învățare profundă (deep learning) autoregresivă unificată, care reprezintă o abordare radical nouă în domeniul multimodal.
Janus 1.3B poate fi testat pe platforma HuggingFace.
În loc să utilizeze encodere separate pentru text și imagini, Janus 1.3B decuplează encodingul vizual în căi independente, dar le integrează într-o singură arhitectură de transformator. Acest design inovator oferă două beneficii majore:
- Flexibilitate îmbunătățită: permite modelului să se adapteze mai ușor la diverse sarcini, fie că este vorba de generarea de imagini din text, de înțelegerea imaginilor sau de sarcini complexe care implică ambele.
- Performanță îmbunătățită: prin evitarea compromisurilor între diferitele sarcini vizuale, Janus 1.3B atinge rezultate superioare în generarea de imagini din text, comparativ cu abordările tradiționale care folosesc un singur encoder vizual.
Procesul de generare a imaginilor din text
Pentru a genera o imagine dintr-un text dat, Janus 1.3B parcurge următorii pași:
Preprocesarea textului: textul de intrare este prelucrat pentru a fi compatibil cu formatul de intrare al modelului. Acest pas poate include tokenizarea, conversia în reprezentări numerice și normalizarea.
Encoding multimodal: textul preprocesat este apoi procesat de către componenta de encoding multimodal a modelului. Aici, textul este transformat într-o reprezentare care poate fi utilizată de arhitectura de transformator pentru a genera o imagine corespunzătoare.
Generarea imaginii: arhitectura de transformator, alimentată cu reprezentarea multimodal a textului, generează imaginea. Acest proces autoregresiv construiește imaginea, pixel cu pixel, sau prin alte metode de generare a imaginilor, în funcție de specificațiile modelului.
Janus 1.3B permite procesarea paralelă a sarcinilor și o înțelegere avansată a contextului semnatic al prompturilor.
Unul din punctele tari ale modelului este generarea unor expresii faciale ale personajelor cu mult mai multe elemente apropiate de realitate.
5. Comparație între modele
Toate cele trei modele sunt extrem de competitive iar imaginile generate de AI sunt extrem de aproape de realitate. Evident fiecare model are plusuri și minusuri.
Vom face câteva teste și vom urmări imaginile generate de fiecare model pentru același prompt.
Pentru început vom dori generarea unei imagini în gen desen cu un raton vesel:
Generate a captivating cinematic image of a cute, curious raccoon in a bustling urban park during
sunset. The scene should be set with warm, orange hues painting the sky, casting a soft glow on
the park's surroundings. The raccoon should be depicted as if it's rummaging through a trash can,
its black mask and bushy ringed tail adding to its charm. The background should include a variety
of urban elements such as benches, trees, and a playground. The image should be of high quality,
with detailed textures and realistic lighting effects.Flux 1.1 a generat o imagine ultra realistă, cu detalii fascinante: fundalul blurat cu soarele care apune, textura animalului cu toate firele de păr vizibile și expresia facială incredibilă.


Stable Diffusion 3.5 Large a adus și mai multe elemente originale în imagine. Pornind de la contextul în care apare ratonul în scenă, modelul a introdus gunoaie pe jos, dar a păstrat efectul artistic de fundal blurat cu personaje care se plimbă prin parc.

Janus 1.3B a generat imaginea cea mai rapidă, dar ratonul nu mai are un aspect realist, ci mai curând de desen animat, deși fundalul a fost generat destul de bine.

Pentru al doilea test vom încerca generarea unor imagini de tip portret, în stil renascentist cu elemente din perioada respectivă.
Vom folosi următorul prompt:
Flux 1.1 generează o imagine mai mult asemănătoare cu o pictură decât cu o fotografie. Sunt remarcabile detaliile costumului purtat de personaj și elementele de fundal ale imaginii.

Stable Diffusion 3.5 Large generează un personaj mult mai extravagant, îmbrăcat în armură, dar și elemente imperiale precum coloane din fundal sau roba purpurie cu detalii aurite.

Janus 1.3B a lăsat orice urmă de realism deoparte. Imaginea pare mai mult o ilustrată a unei cărți de aventuri, iar personajul și fundalul par mai mult din secolul al 19-lea decât din secolele renașterii.

Ultimul test de azi urmărește obținerea imaginii unui oraș futurist în stilul elementelor filmului science-fiction Blare Runner:
Generate a captivating cinematic image of a futuristic city, with elements of cyberpunk, set in a
world reminiscent of the Blade Runner movie. The scene should be set during a heavy downpour, with
rain pouring down on neon-lit streets and towering skyscrapers. The cityscape should include
elements such as flying cars, holographic billboards, and futuristic architecture. The image
should be of high quality, with detailed textures and realistic lighting effects, creating a sense
of immersion in the cyberpunk world.Flux 1.1 generează o imagine conformă cu instrucțiunile date, dar cu unele inadvertențe evidente: mașinile circulă pe ambele sensuri unele spre celelalte. Totuși scena conține toate elemente cerute:

Stable Diffusion 3.5 Large generează o imagine asemănătoare cu posterul unui film SF din anii 1980:

În fine, Janus 1.3B generează o imagine care seamănă mai mult cu o pictură în ulei:

Am urmărit comportamentul modelelor în funcție de calitate, viteză și versatilitate.
Calitatea imaginilor
- Flux 1.1: Excelează în detalii fine și texturi naturale;
- Stable Diffusion 3.5 Large: Oferă cel mai bun echilibru între calitate și viteză;
- Janus 1.3B: Superior în redarea expresiilor și anatomiei umane generale.
Viteza de procesare
- Flux 1.1: Timp mediu de procesare, dar rezultate consistente;
- Stable Diffusion 3.5 Large: Cel mai rapid dintre cele trei;
- Janus 1.3B: Procesare mai lentă, dar scenele generate conțin elemente originale generale, nu și detalii..
Versatilitate
- Flux 1.1: Excelent pentru scene naturale și peisaje;
- Stable Diffusion 3.5 Large: Versatil în multiple stiluri și contexte;
- Janus 1.3B: Specializat în subiecte umane și portrete, imaginile generate seamănă mai mult cu picturi.
În opinia noastră câștigă detașat Flux 1.1 care a generat imaginile cele mai apropiate de ce ne-am dorit.
6. Concluzii
Imaginile generate de AI sunt din ce în ce mai utilizate în mediul pentru că se pot genera extrem de ușor, sunt din ce în ce mai ieftine, calitatea crește și devin din ce în ce mai greu de distins de imaginile reale.
Gama de utilizare este diversă:
- artă digitală (animație, ilustrate etc);
- design și marketing (materiale publicitare, design de produs, social media, reimaginarea unor scene reale – de pildă colorarea sau mobiliarea virtuală a unui apartament);
- producție media (suport pentru filme și jocuri, suport pentru povești, generarea de fundaluri pentru materiale multimedia etc).
Desigur, creatorii tradiționali se împotrivesc tehnologiei generative, dar până la urmă imaginile generate de AI pot fi asimilate unor noi oportunități ca de fiecare dată când apar noi tehnologii. Să nu uităm că toate imaginile au la bază factorul uman, care stabilește promptul/instrucțiunile și care modifică constant imaginile până ajunge la rezultatul dorit.
Fiecare dintre modele AI prezentat aduce contribuții valoroase în domeniul generării de imagini AI:
- Flux 1.1 stabilește noi standarde pentru calitatea detaliilor;
- Stable Diffusion 3.5 Large oferă cel mai bun raport performanță-versatilitate;
- Janus 1.3B deschide noi posibilități în generarea de conținut centrat pe subiecte umane.
Alegerea modelului potrivit depinde de cerințele specifice ale proiectului, considerând factori precum:
- Tipul de conținut dorit;
- Timpul disponibil pentru generare;
- Necesitățile de control și editare;
- Resursele computaționale disponibile;
- Costul de producție.
Pe măsură ce tehnologia continuă să evolueze, putem aștepta îmbunătățiri semnificative în toate aspectele generării de imagini AI, de la calitate și viteză până la ușurința în utilizare și controlul asupra rezultatelor finale.