Uneori dorim ca să analizăm rapid un text și să extragem doar anumite informații dacă acestea sunt prezente în text.
Un exemplu de situație este descrierea unui hotel care poate fi făcută într-un limbaj orientat mai mult spre marketing și vânzare, noi fiind interesați strict de prezența unor facilități precum piscine, saune sau număr de restaurante.
Vom folosi în testele de azi noul model Phi 3.5 pe care îl vom programa să identifice datele după un model json prestabilt.
Phi 3.5 va rula pe un server Ollama instalat local.
Codare
Pentru acest test vom folosi python și vom seta comportamentul modelului AI și textul care urmează să fie analizat în două fișiere disticte: rol.txt și context.txt.
Pentru a putea folosi codul și pe alte tipuri de date vom folosi și librariile python care citesc PDF-uri sau fișiere docx.
from openai import OpenAI
import openpyxl
from openpyxl import load_workbook
import docx
import PyPDF2
Adăugăm o funcție care permite citirea conținutului din fișiere terțe:
def read_file_content(file_path):
file_extension = file_path.split('.')[-1]
if file_extension == 'docx':
return read_docx_file(file_path)
elif file_extension == 'pdf':
pdf_file_obj = open(file_path, 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj)
text = ''
for page in range(pdf_reader.numPages):
text += pdf_reader.getPage(page).extractText()
return text
elif file_extension == 'xlsx':
workbook = load_workbook(filename=file_path)
sheet = workbook.active
text = ''
for row in sheet.iter_rows():
for cell in row:
text += str(cell.value) + ' '
return text
elif file_extension == 'txt':
with open(file_path, 'r') as file:
text = file.read()
return text
else:
return 'Unsupported file format'Definim o altă funcție care permite utilizarea modelului Phi 3.5 cu rolul și contextul stabilit:
def analiza(context, rol):
stream = client.chat.completions.create(
model="phi3.5:latest", # this field is currently unused
messages=[
{"role": "system", "content": rol},
{"role": "user", "content": context}
],
temperature=0.8,
stream=True,
)
raspuns = ""
for chunk in stream:
raspuns += str(chunk.choices[0].delta.content)
print(chunk.choices[0].delta.content, end="")
return raspunsSetăm clientul Ollama:
client = OpenAI(base_url='http://localhost:11434/v1/',api_key='ollama')
Exemplul 1 – analiza descierii unui model AI
Pentru început vom testa codul cu următorul text care descriere un model AI furnizat de Mistral:
We introduce Mistral 7B, a 7–billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms the best open 13B model (Llama 2) across all evaluated benchmarks, and the best released 34B model (Llama 1) in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B – Instruct, that surpasses Llama 2 13B – chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license. Ne interesează numele modelului, parametri și locurile unde ar putea fi utilizat, deci putem genera schema următoare:
Identify information in context and reply with results using this schema applied to the context provided:
schema = """{
"Model": {
"Name": "",
"Number of parameters": "",
"Number of max token": "",
"Architecture": []
},
"Usage": {
"Use case": [],
"Licence": ""
}
}"""
Reply only with the schema provided. Do not add reply with any other information.
Am instruit modelul să răspundă doar cu json-ul completat și să nu adauge nici o informație în plus.
Rezultatul rulării:
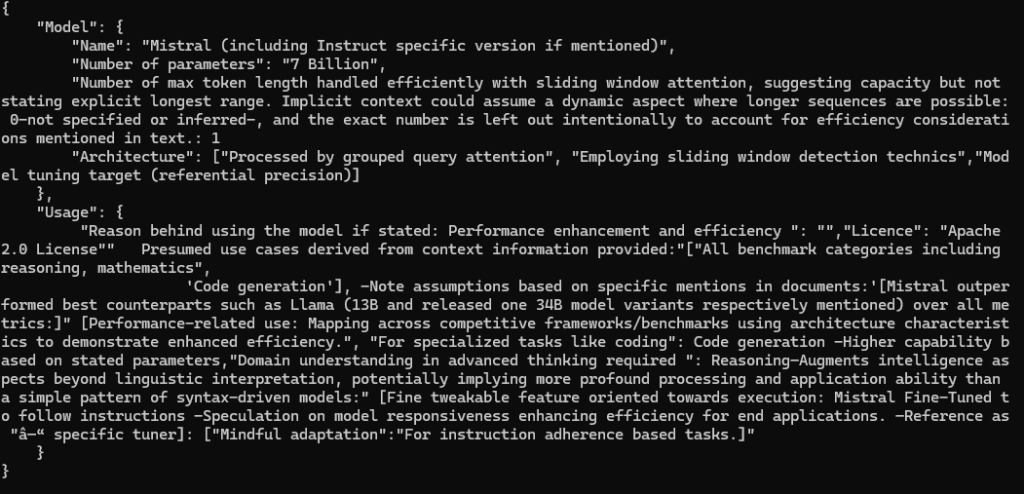
{
"Model": {
"Name": "Mistral (including Instruct specific version if mentioned)",
"Number of parameters": "7 Billion",
"Number of max token length handled efficiently with sliding window attention, suggesting capacity but not stating explicit longest range. Implicit context could assume a dynamic aspect where longer sequences are possible: 0-not specified or inferred-, and the exact number is left out intentionally to account for efficiency considerations mentioned in text.: 1
"Architecture": ["Processed by grouped query attention", "Employing sliding window detection technics","Model tuning target (referential precision)]
},
"Usage": {
"Reason behind using the model if stated: Performance enhancement and efficiency ": "","Licence": "Apache 2.0 License"" Presumed use cases derived from context information provided:"["All benchmark categories including reasoning, mathematics",
'Code generation'], -Note assumptions based on specific mentions in documents:'[Mistral outperformed best counterparts such as Llama (13B and released one 34B model variants respectively mentioned) over all metrics:]" [Performance-related use: Mapping across competitive frameworks/benchmarks using architecture characteristics to demonstrate enhanced efficiency.", "For specialized tasks like coding": Code generation -Higher capability based on stated parameters,"Domain understanding in advanced thinking required ": Reasoning–Augments intelligence aspects beyond linguistic interpretation, potentially implying more profound processing and application ability than a simple pattern of syntax-driven models:" [Fine tweakable feature oriented towards execution: Mistral Fine-Tuned to follow instructions -Speculation on model responsiveness enhancing efficiency for end applications. –Reference as "â—“ specific tuner]: ["Mindful adaptation":"For instruction adherence based tasks.]"
}
}Phi 3.5 a identificat corect toate elementele cerute.
Exemplul 2. Extragerea datelor din descrierea unui hotel
O situație mai practică este atunci când avem la dispoziție o bază de date cu descrieri de hoteluri și dorim să adăugăm o filtrare pentru a permite o filtrare după anumite criterii.
Dacă facem o căutare SQL va trebui să căutăm după termeni fixi și în funcție de mărimea bazei de date acest proces poate însemna un consum de timp destul de mare.
Un exemplu de descriere este:
Detalii cazare
Cuibărit la 500 metri de centrul orașului, hotelul asigură un acces ușor înspre tot ce are de oferit această destinație. Un total de 250 camere de oaspeți sunt disponibile pentru confortul acestora. Această reşedinţă a fost recondiţionată în anul 2001. Toți oaspeții care stau la această proprietate pot profita în spaţiile publice de conexiune Wi-Fi. Toți oaspeții care stau la această proprietate se vor bucura de recepţia deschisă 24 de ore. Din nefericire, nu există camere în care oaspeţii să poată solicita un pat suplimentar pentru cei mici. Mai mult, o parcare este disponibilă în incintă pentru un plus de confort al oaspeţilor. Aceasta este o proprietate ecologică. Opţiunile de divertisment puse la dispoziţie vor impresiona cu siguranţă toţi călătorii. Hotelul poate percepe o taxă pentru unele dintre aceste servicii.În testul nostru ne interesează să știm anul renovării și capacitatea hotelului, deci stabilim următoarele instrucțiuni:
Identify information in context and reply with results using this schema applied to the context provided:
schema = """{
"Cazare": {
"Anul renovarii ": "",
"Numar de camere": ""
}
}"""
Reply only with the schema provided. Do not add reply with any other information.
După cum se observă am stabilit instrucțiunile în limba română și limba engleză, dar pentru model acest lucru este irelevant.
Modelul Phi 3.5 răspunde în felul următor:

{
"Cazare": {
"Anul renovarii ": "2001",
"Numar de camere": "250"
}
}
Putem astfel parcurge întreaga bază de date, identifica toate facilitățile dorite pe care le putem marca cu True/False și optimiza apoi toate căutările.
Concluzie
Modelul Phi 3.5 este extrem de stabil în ciuda dimensiunii lui reduse de aproximat 2.5 GB. El poate fi rulat chiar local pentru a executa sarcini complexe, cu un cost extrem de redus.