



Modele mari de limbaj (LLMs) au realizat progrese semnificative în logica matematică și demonstrarea teoremelor, dar încă întâmpină obstacole semnificative în rezolvarea problemelor complexe.
Difficultatea principală constă în necesitatea ca modelul să înțeleagă simultan sintaxa și semantica cerințelor, punând pe același plan logicamatematică abstractă cu reprezentările matematice precise.
Aceste saricini complexe necesită o înțelegere semnificativă a cerințelor de codare a conceptelor matematice care reprinzintă provocări majore pentru toate sistemele AI din prezent.
Cercetătorii din DeepSeek-AI au lansat modelul DeepSeek-Prover-V1.5, care combină avantajele tehnicilor generative cu o strategie de împărțire a problemelor în subprobleme mai mici și de rezolvare succesivă a acestora.
Modelul începe rezolvarea problemei întregi conform cerințelor inițiale și apoi verifică dacă scopul a fost atins de râspuns. Dacă este detectată o eroare, codul este segmentat la această primă eroare și prima bucată de cod considerată corectă este folosită ca instrucțiune pentru continuarea rezolvării problemei.

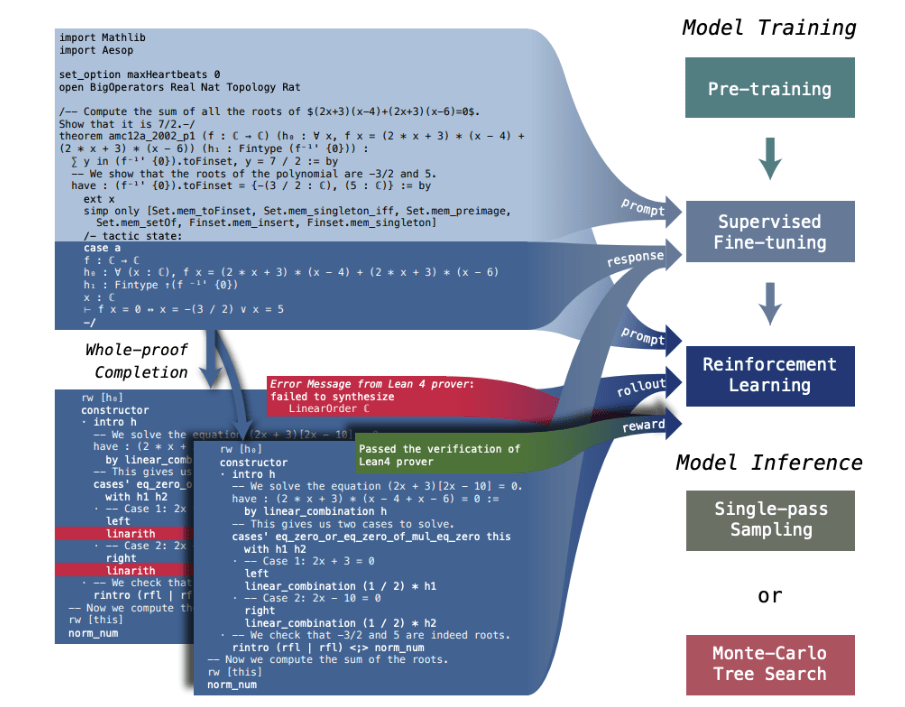
Această model aduce următoarele noi îmbunătățiri:
- Pre antrenare a modelui, respectic modelul DeepSeek-Prover-V1.5 este antrenat intens pe date matematice și de codare cu accent accent pe limbaje formale ca Lean, Isabelle și Metamath;
- Ajustări supervizate prin folosirea implementărilor din DeepSeek-Coder V2 236B pentru un limbaj natural orientat pe înțelegerea cerințelor și prin introducerea punctelor intermediare de verificare a rezolvării codului prin metoda Lean 4.
DeepSeek-Prover-V1.5 dovedește progrese semnificative în înțelegerea problemelor matematice și în capacitatea de a rezolva probleme complexe.

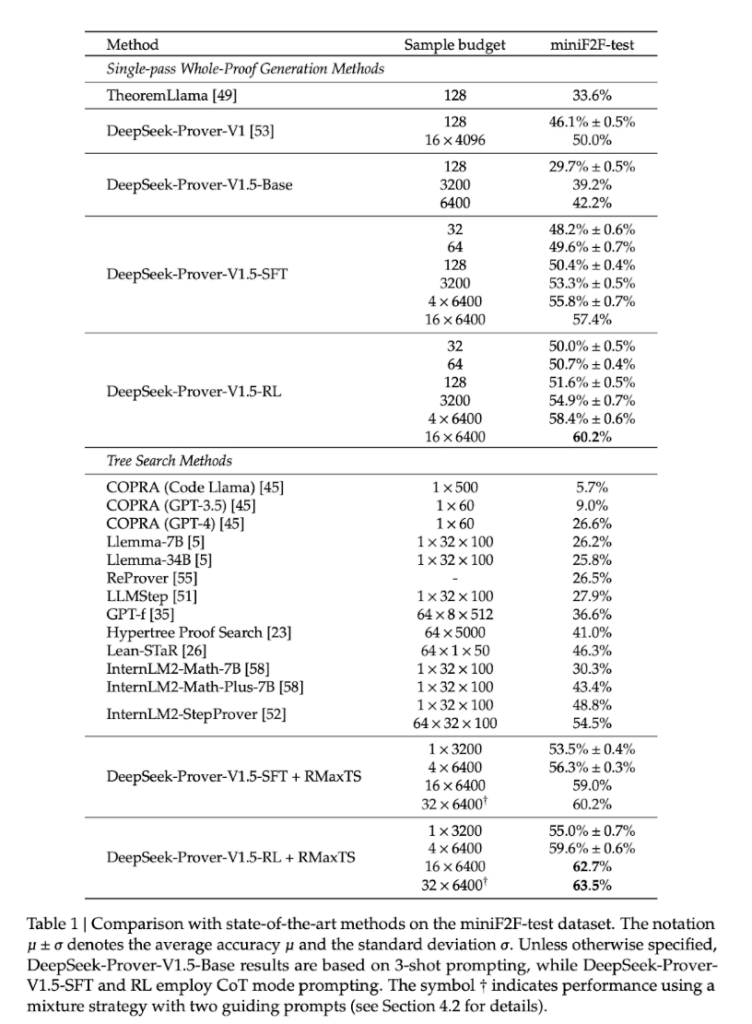
demonstrează progrese semnificative în demonstrarea teoremei formale peste mai multe benchsmarkuri. Pe data miniF2F-test, DeepSeek-Prover-V1.5-RL a obținut o rată de trecere de 60,2% pentru generația completă a demonstrationului într-o singură pasare, marind cu 10,2 puncte percentageale față de predecesorul său. Cu un buget limitat de eșantionare de 128 de încercări, a demonstrat 51,6% din problemele, depășind alți metodi de generație completă și egalând metodele avansate de căutare arborescentă. Când îmbunătățit cu căutarea arborelui RMaxTS, DeepSeek-Prover-V1.5-RL a obținut o rată de trecere de 62,7%, stabilind un nou record în formal demonstration theory using Lean 4. Bazeaza DeepSeek-Prover-V1.5 pe DeepSeek-Prover-V1.5-Base și trece prin pre-Înregistrare specializată, regăzirea supervisionată completă și pregătirea prin reinforceament via GRPO. Modelul include RMaxTS, o variantă inovatoare a căutării arborelui Monte-Carlo, pentru îmbunățarea rezolvării problemelor prin explorare extensivă. Acest cadru stabilesc un pipeline AlphaZero pentru demonstrarea teoremei formale, utilizând iterarea expert și date sintetic