



Atunci când vrem să rulăm un Large Language Model local cele mai la îndemână modalități sunt Ollama, LM Studio sau VLLM.
Ollama este conceput pentru a rula modele LLM extrem de ușor, ceea ce îl face extrem de atractiv pentru dezvoltatori sau utilizatori individuali care doresc să testeze software-ul bazat pe AI înainte de a-l introduce în producție sau care pur și simplu doresc rularea unor aplicații AI strict local.
În acest articol vom discuta despre cum se instalează Ollama și ce trebuie făcut pentru a rula un prim LLM.
Instalare
Ollama poate fi instalat din github sau direct de pe pagina lui oficială pe oricare din următoarele sisteme de operare: Windows (începând cu versiunea 10), Linux sau macOs.


Vom considera în continuare instalarea pe un sistem Windows și apoi pe un sistem care rulează Ubuntu.
Instalarea în Windows 11
Atunci când se optează pentru instalarea în Windows se va descarca aplicația OllamaSetup. După rularea acestei aplicații o nouă iconiță in dreapta jos a ecranului va semnaliza că Ollama a fost instalat.

De asemenea iconița ne va semnala când Ollama necesită o actualizare.
Un lucru important de știut este că Ollama va folosi folderul C:\\Users\%username%\.ollama\models pentru a descărca modelele LLM. Această situație poate duce rapid la epuizarea spațiului disponibil pe discul C și implicit la probleme în funcționarea Windows.
O soluție este setarea unui alt director implicit și pentru aceasta putem seta o variabilă de sistem denumită OLLAMA_MODELS având ca valoare noul director.

După instalare Ollama rulează în fundal și poate fi apelat din Command Prompter/PowerShell sau din oricare din aplicațiile de comunicare dorite de utilizator
Instalarea in Ubuntu
Similar instalării din Windows, pentru sistemele Linux Ollama pune la dispoziție un shell care face setarea aplicației în mod automat:
curl -fsSL https://ollama.com/install.sh | shDupă instalare, Ollama poate fi adaugat ca serviciu cu rulare implicită sau poate fi rulat manual prin apelarea directă a funcției Ollama

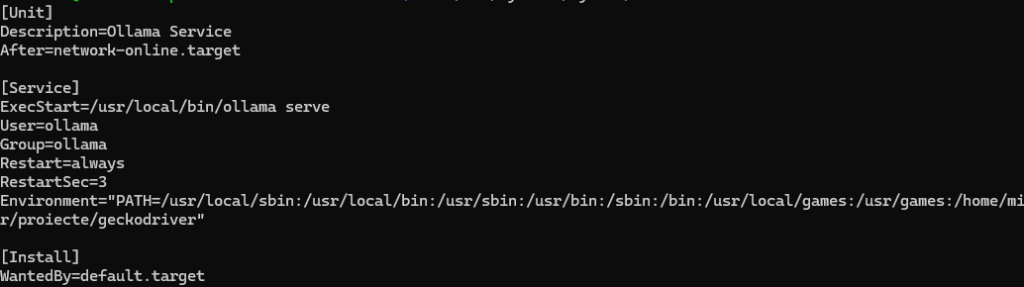
De asemenea se poate stabili alt folder pentru stocarea modelelor folosind aceeași variabilă de sistem OLLAMA_MODELS


În exemplul precedent s-a folosit variabila OLLAMA_MODELS pentru a preciza ca modelele se încarcă dintr-un drive NVME și câ aplicațîa ar trebui să comunice pe toate interfețele pe portul 11434 (implicit)
Comenzi frecvente Ollama
Indiferent de sistemul de operare folosit, Ollama dispune de un set de comenzi care permite rularea în mod direct a unui model, în mod server sau efectuarea de opeațiuni de descărcare/eliminare a unor modele.
Modelele dispnibile public pot fi descărcate tot de pe site-ul Ollama din secțiunea modele:
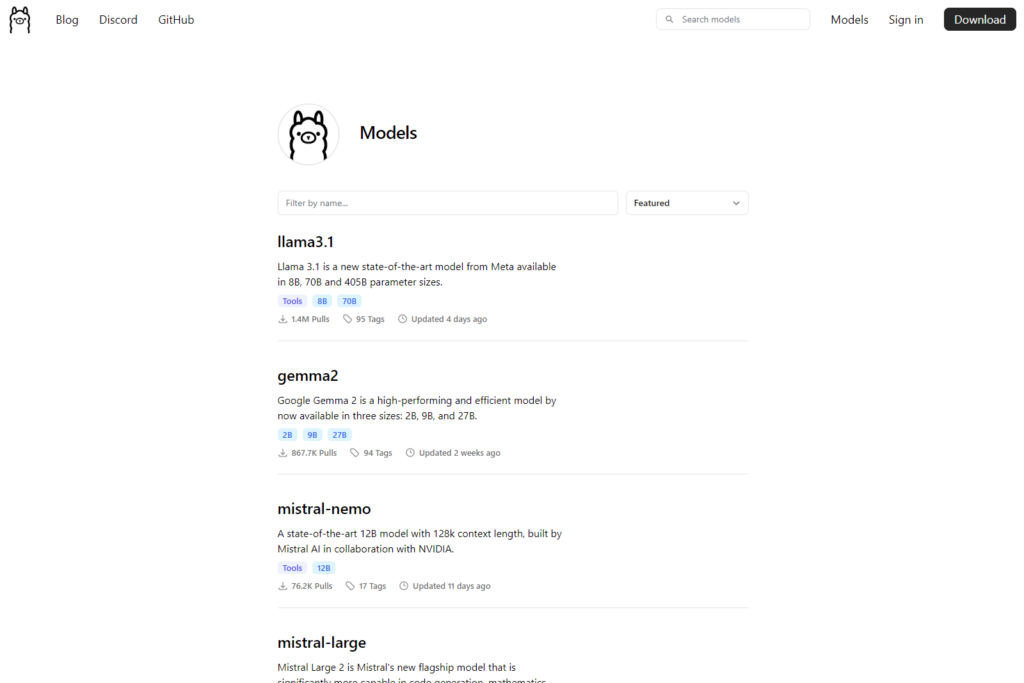
În funcție de tipul de cuantizare există mai multe variante disponibile care pot fi descărcate local:

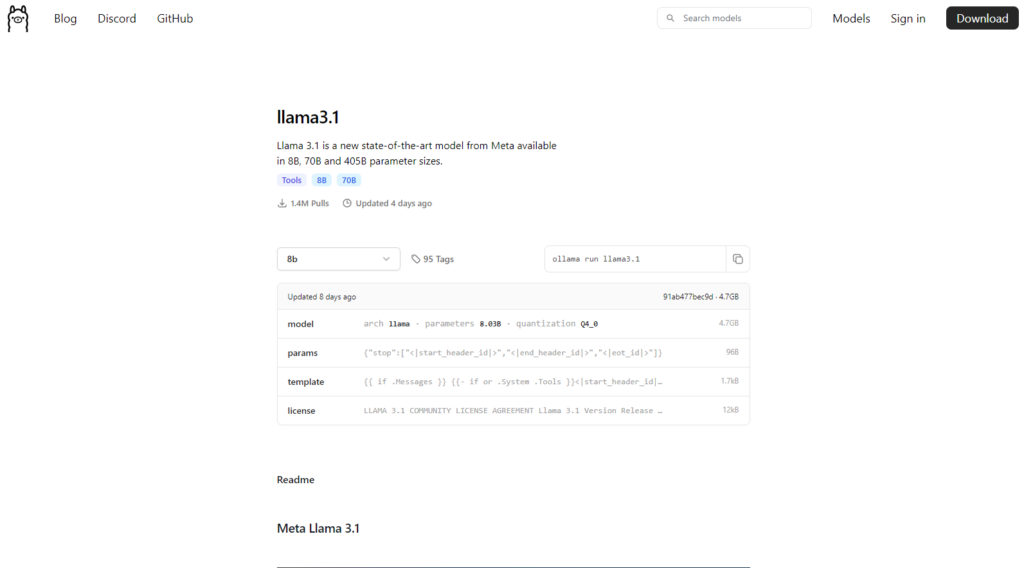
Atunci când descărcăm un model totuși trebuie să ținem cont de capacitățile tehnice ale sistemului nostru, respectiv de placa grafică și de capacitatea RAM disponibile.
Pentru rularea LLM-urile vă recomandăm utilizarea placilor grafice NVIDIA și un model care să încapă complet în VRAM-ul plăcii video. Cu toate acestea, Ollama va folosi și RAM sistemului dacă modelul are o dimensiune prea mare, dar în acest caz timpul de răspuns va scădea în mod simțitor.
Pentru descărcarea unui model se poate folosi comanda:


sau direct:

Pentru a lista modelele decărcate deja folosim comanda ollama ls

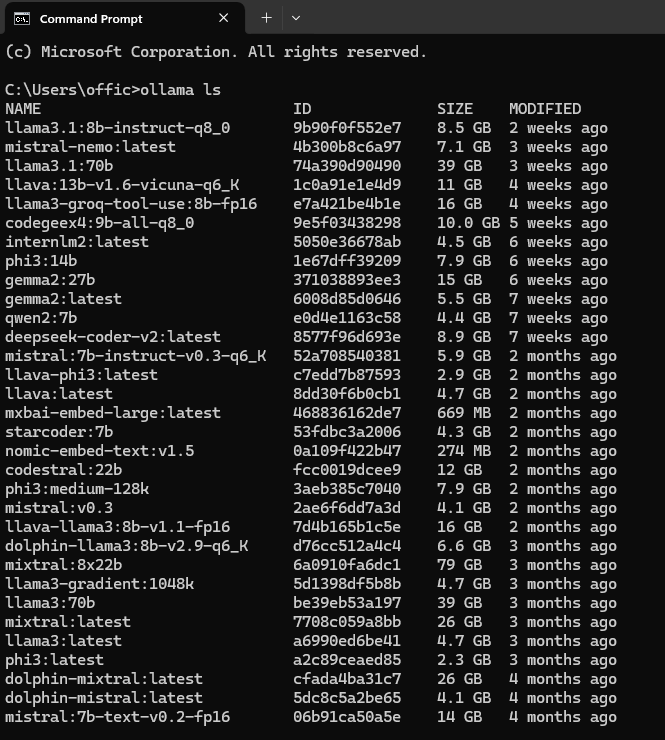
Pentru a elimina un model folosim comanda ollama rm și numele modelului.
Discuții cu modelele Ollama
Pentru o interacțiune directă cu un model Ollama putem apela funcția ollama run model sau putem folosi o aplicație dedicată.


În fucție de complexitatea modelului și de capacitatea sistemului, modelul va da un răspuns imediat întrebărilor noastre.
Trebuie ținut cont însă că modelul va răspunde legat de lucrurile pe care le cunoaște, cu care a fost antrenat și va tinde să fabuleze atunci când este întrebat lucruri despre care nu știe nimic. De asemenea, în funcție de cuantizarea modelului și precizia acestuia poate avea de suferit.
Modelul nu va da răspunsuri legate de informații în timp real decât dacă îl înzestrăm cu mijloacele necesare (API-uri).
Aplicații Ollama disponibile în Windows
Dacă dorim să discutăm cu modelele LLM într-un mod mai plăcut vizual putem folosi aplicații dedicate,care pot fi mai mult sau mai puțin complexe.
Astfel putem avea aplicații simple care permit dialogul sau altele care permit adăugarea de documente și obținerea de informații din acestea (exemplu AnythingLLM).
Dacă vrem doar un dialog simplu putem utiliza extensia Chrome Chat with Ollama disponibilă gratuit din Magazinul de extensii.

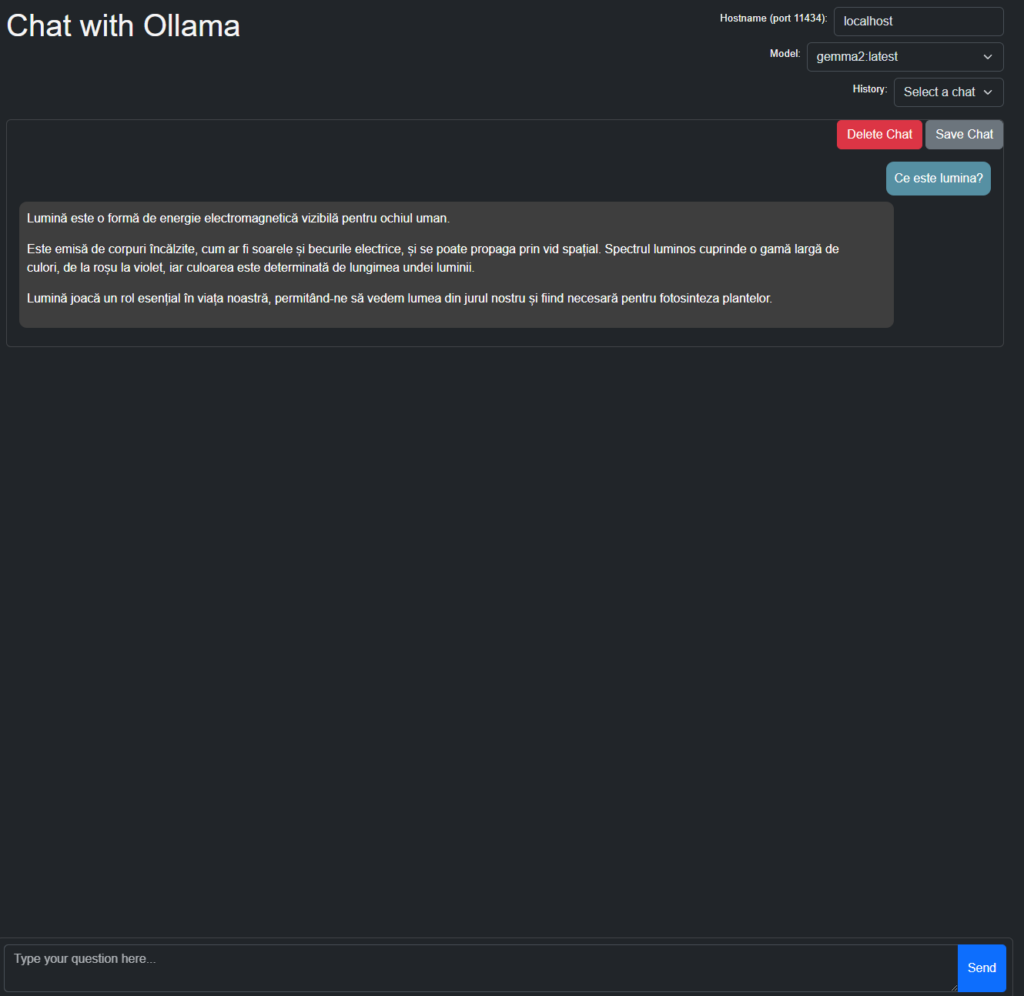
Extensia folosește Ollama instalat local în Windows și permite selecția modelului cu care se dorește interacțiunea.

În articolele viitoare vom discuta despre cum putem interacționa cu modelele LLM locale sau din internet folosind python sau alte aplicații dedicate.