Cum fi dacă, în loc să alimentezi modelul cu text întreg, i-ai arăta doar o imagine a acestuia? Aceasta este ideea fundamentală din spatele DeepSeek-OCR, un model care nu tratează viziunea ca pe o funcționalitate secundară, ci ca pe un strat de compresie pentru text. Echipa DeepSeek numește acest concept „Context Optical Compression” – practic, actul de a reprezenta conținut textual lung prin imagini și de a-l decoda înapoi folosind înțelegerea vizual-lingvistică.
La prima vedere, pare contraintuitiv. De ce ar ajuta transformarea textului în imagine? Însă intuiția este simplă: o imagine poate conține mult text fiind reprezentată prin mult mai puțini tokeni. Unde o pagină de text ar putea ocupa 2.000-5.000 de tokeni text, aceeași pagină redată ca imagine ar putea necesita doar 200-400 de tokeni vizuali. Asta înseamnă o compresie de aproximativ 10×.
Modelele lingvistice mari (LLM-urile) au o slăbiciune fundamentală care le urmărește de la început: lungimea. Când alimentezi un model cu un document de 100.000 de tokeni, vei simți imediat efectele – latență crescută, consum masiv de memorie și costuri în spirală. Problema nu este neapărat vina modelelor; mecanismul de atenție al transformerilor scalează pătratic cu lungimea secvenței, făcând procesarea textului lung extrem de costisitoare computațional. DeepSeek-OCR pare că a rezolvat tocmai acest aspect.
Arhitectura DeepSeek-OCR: Un sistem în două etaje
DeepSeek-OCR este un sistem cu două componente principale: DeepEncoder (un encoder vizual) și DeepSeek-3B-MoE (un decoder). DeepEncoder, cu aproximativ 380 milioane de parametri, este inima sistemului și combinează SAM-base (80M parametri) pentru percepția locală folosind window attention cu CLIP-large (300M parametri) pentru înțelegerea globală folosind dense attention. Între aceste două componente se află un compressor convoluțional 16×, care reduce tokenii vizuali înainte de a-i transmite părții cu atenție globală densă.
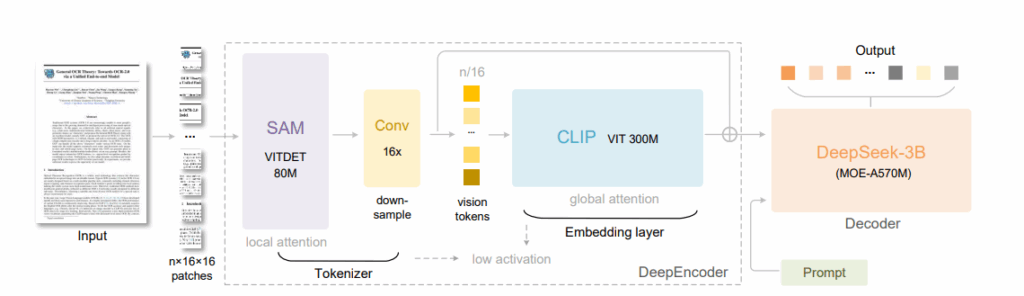
Să luăm un exemplu concret: când introduci o imagine de 1024×1024 pixeli, aceasta este împărțită în 4.096 de patch-uri. După trecerea prin compressorul 16×, rămân doar 256 de tokeni. Modelul evită astfel explozia în memoria de activare, tipică pentru vision transformers.
Partea de decoder folosește arhitectura DeepSeek-3B-MoE cu aproximativ 570M parametri activi, unde se activează 6 din 64 de experți per pas, plus 2 experți comuni. Este un Mixture-of-Experts eficient care reconstruiește textul din tokenii vizuali compresiați. Această abordare oferă capacitatea expresivă a unui model de 3 miliarde de parametri, dar cu eficiența de inferență a unui model mic de 500 milioane.
Fluxul este elegant în simplitatea sa: imaginea documentului trece prin DeepEncoder, este comprimată în tokeni vizuali, iar apoi decoder-ul MoE reconstruiește textul. Ceea ce face această arhitectură specială este că a fost antrenată pe o varietate masivă de date – documente, ecuații, grafice, structuri chimice și chiar PDF-uri multilingve.
Design multi-rezoluție: Flexibilitate pentru orice scenariu
Una dintre cele mai interesante caracteristici ale DeepSeek-OCR este suportul pentru multiple moduri de rezoluție, permițând ajustarea dinamică a compresiei în funcție de densitatea textului și layoutul paginii. Sistemul oferă șase moduri diferite de operare, fiecare optimizat pentru scenarii specifice.
Modurile native includ patru variante: Tiny (512×512, 64 tokeni), Small (640×640, 100 tokeni), Base (1024×1024, 256 tokeni) și Large (1280×1280, 400 tokeni). Pentru modurile Tiny și Small, imaginile sunt redimensionate direct pentru a evita risipa de tokeni vizuali, în timp ce pentru Base și Large, imaginile sunt completate cu padding pentru a păstra raportul de aspect original.
Modurile Gundam reprezintă rezoluția dinamică și sunt gândite special pentru aplicații practice, în special pentru imagini cu rezoluție ultra-înaltă precum ziarele. Modul Gundam constă din n×640×640 tile-uri (vederi locale) plus o vedere globală de 1024×1024. Numărul de tokeni vizuali este calculat ca n×100+256, unde n reprezintă numărul de tile-uri, controlat între 2 și 9.

Această tehnică de segmentare în zone mai mici acționează ca un strat adițional de atenție localizată, diminuând și mai mult memoria necesară pentru activare. Ceea ce este remarcabil este că, datorită rezoluțiilor native relativ mari, imaginile nu sunt fragmentate excesiv – spre deosebire de alte sisteme care folosesc rezoluții native mici (sub 512×512) și ajung să fragmenteze excesiv imaginile mari.
Toată această flexibilitate înseamnă că același model DeepSeek-OCR poate fi folosit pentru diverse scenarii: de la documente simple care necesită doar 64 de tokeni vizuali, până la ziare complexe care necesită modul Gundam cu peste 1.000 de tokeni.
Antrenament la scară industrială
Procesul de antrenament al DeepSeek-OCR s-a desfășurat în două etape principale folosind platforma HAI-LLM, pe 20 de noduri cu câte 8 GPU-uri A100-40G fiecare. În prima etapă, DeepEncoder a fost antrenat independent folosind predicția next-token pe perechi imagine-text. În a doua etapă, întregul sistem encoder-decoder a fost antrenat împreună cu un mix de date OCR, vizuale și doar text.
Cifrele sunt impresionante: throughput-ul ajunge la aproximativ 70-90 miliarde tokeni pe zi, cu un batch size global de 640 și o rată de învățare de 3e-5 folosind optimizatorul AdamW. Această capacitate de procesare permite modelului să genereze peste 200.000 de pagini de date de antrenament pe zi pe un singur GPU A100, ceea ce înseamnă aproximativ 33 de milioane de pagini pe zi pe clusterul complet.
Compoziția datelor de antrenament este la fel de interesantă: datele OCR 1.0 (30M pagini) constau din PDF-uri reale de documente în peste 100 de limbi. Datele OCR 2.0 sunt sintetice dar structurate, incluzând grafice, formule, geometrie. Date vizuale generale (20%) pentru a păstra capacitățile de înțelegere a imaginilor. Date doar text (10%) pentru a păstra calitatea lingvistică.
Pentru datele de documente, echipa a creat două tipuri de adnotări: adnotări grosiere extrase direct cu fitz pentru recunoașterea textului optic, special în limbi minoritare, și adnotări fine pentru 2M pagini în chineză și engleză, etichetate folosind modele avansate de layout și OCR pentru a construi date intercalate de detecție și recunoaștere.
Un aspect fascinant este că modelul suportă aproape 100 de limbi pentru documentele PDF, iar datele OCR 2.0 includ capacități speciale: parsarea graficelor în tabele HTML, recunoașterea formulelor chimice și înțelegerea geometriei plane folosind dicționare structurate.
Performanță și rezultate: compresia eficientă devine realitate
Rezultatele DeepSeek-OCR sunt impresionante și validează conceptul de compresie optică a contextului. Pe benchmark-ul Fox, modelul atinge o precizie de peste 97% la decodare OCR când rata de compresie este sub 10× (numărul de tokeni text este de maximum 10 ori mai mare decât numărul de tokeni vizuali). Chiar și la o rată de compresie de 20×, acuratețea OCR rămâne la aproximativ 60%.
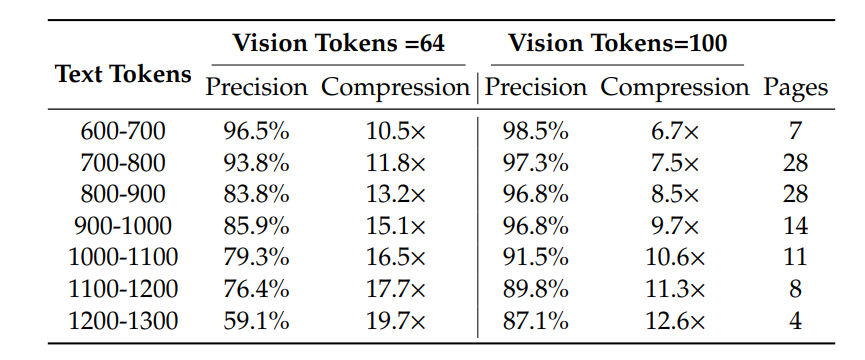
Pe benchmark-ul practic OmniDocBench, DeepSeek-OCR depășește GOT-OCR2.0 (care folosește 256 tokeni/pagină) folosind doar 100 tokeni vizuali, și întrece MinerU2.0 (care folosește peste 6.000 tokeni per pagină în medie) în timp ce utilizează mai puțin de 800 tokeni vizuali. Acesta este un salt semnificativ în eficiență – același nivel de performanță cu o fracțiune din resursele computaționale.
Analiza pe diferite tipuri de documente relevă pattern-uri interesante: unele categorii precum slide-urile necesită foarte puțini tokeni (doar 64) pentru performanță satisfăcătoare. Pentru cărți și rapoarte, DeepSeek-OCR poate atinge performanță bună cu doar 100 tokeni vizuali. Pentru ziare însă, este necesar modul Gundam sau Gundam-master pentru distanțe de editare acceptabile, deoarece tokenul text în ziare este de 4-5.000, depășind cu mult compresia 10× a altor moduri.
În producție, DeepSeek-OCR poate genera date de antrenament pentru LLM-uri/VLM-uri la scară de peste 200.000 pagini pe zi pe un singur A100-40G, ajungând la 33 milioane pagini pe zi pe 20 de noduri. Această capacitate de generare de date îl transformă într-un motor dual-purpose – atât un sistem OCR de producție, cât și un generator de date pentru preantrenarea altor modele.

Capacitățile de „deep parsing” ale modelului sunt la fel de notabile, permițându-i să parseze grafice, formule chimice, figuri geometrice simple și chiar imagini naturale, toate cu un singur prompt unificat.
Implicații pentru viitor: mecanisme de memorare și context infinit
Poate cea mai fascinantă implicație a DeepSeek-OCR nu este doar eficiența sa actuală, ci direcția pe care o deschide pentru viitorul LLM-urilor. Conceptul de compresie optică a contextului oferă o soluție elegantă la problema vechiului context lung: în loc să extindem continuu ferestrele de atenție, compresia vizuală a contextului permite un mecanism natural de „uitare” care mimează modul în care funcționează memoria umană.
Gândiți-vă astfel: pentru contexte mai vechi într-o conversație în mai mulți pași, ar putea fi redimensionate progresiv imaginile generate pentru a reduce și mai mult consumul de tokeni. Această abordare se inspiră din paralela naturală între degradarea memoriei umane în timp și degradarea percepției vizuale pe distanță spațială – ambele prezintă pattern-uri similare de pierdere progresivă a informației. Contextele recente mențin fidelitate înaltă, în timp ce amintirile îndepărtate se estompează natural prin rate de compresie crescute.
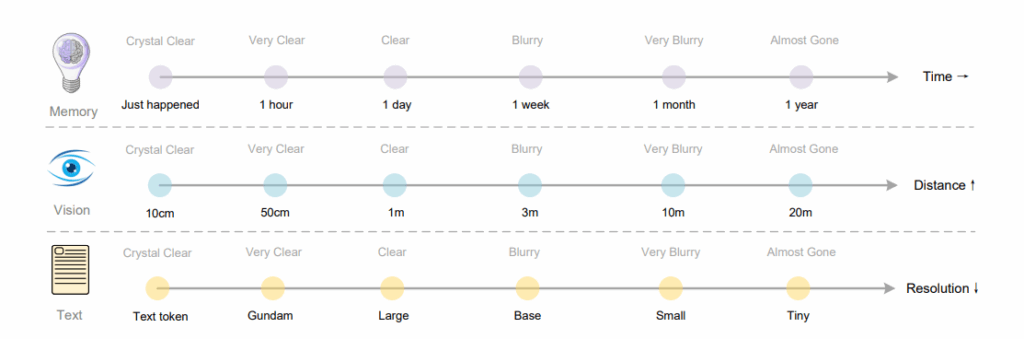
Imaginați-vă un sistem unde istoricul unei conversații nu este stocat în tokeni text, ci în imagini – comprimate, stratificate și estompându-se treptat, exact ca amintirile noastre. Context recent = imagine clară (mai mulți tokeni). Context vechi = imagine neclară (mai puțini tokeni). Aceasta nu este doar o optimizare tehnică; este o modelare a modului în care funcționează de fapt memoria umană.
Pentru dezvoltatorii de LLM-uri, această abordare înseamnă: memorie mai ieftină (tokenii vizuali sunt compacți), inferență mai rapidă (mai puțini tokeni = mai puține operații), uitare naturală (contextul vechi poate fi sub-eșantionat), și fuziune multimodală mai ușoară (modelul vede deja textul ca imagine).
Deși această explorare inițială arată potențial pentru procesarea contextului ultra-lung scalabil, unde contextele recente păstrează rezoluție înaltă și contextele vechi consumă mai puține resurse, autorii recunosc că aceasta este o lucrare în stadiu incipient care necesită investigații ulterioare.
Concluzie: O nouă paradigmă pentru procesarea textului lung
DeepSeek-OCR nu este doar un alt model OCR performant – este o demonstrație funcțională a unei idei fundamental noi: textul poate fi stocat și procesat mai eficient ca viziune decât ca secvențe lingvistice pure. Rezultatele demonstrează că modelele lingvistice compacte pot învăța efectiv să decodeze reprezentări vizuale comprimate, sugerând că LLM-urile mai mari ar putea dobândi cu ușurință capacități similare prin design de preantrenament adecvat.
Cu o arhitectură nouă (DeepEncoder) care menține memorie de activare redusă și tokeni vizuali minimi chiar și cu intrări de rezoluție înaltă, DeepSeek-OCR atinge performanță state-of-the-art pe benchmark-uri OCR folosind cei mai puțini tokeni vizuali dintre modelele end-to-end. Capacitatea sa de a genera 33 milioane de pagini de date pe zi îl face un instrument indispensabil pentru antrenarea viitoarelor generații de LLM-uri și VLM-uri.
Dar poate cel mai important aspect este direcția de cercetare pe care o deschide. Deși focalizat pe OCR ca proof-of-concept, această paradigmă deschide noi posibilități pentru regândirea modului în care modalitățile vizuale și lingvistice pot fi combinate sinergic pentru a îmbunătăți eficiența computațională în procesarea textului la scară largă și sistemele agent.
În viitor, LLM-urile ar putea păstra memoria lor pe termen lung nu în tokeni, ci în imagini – comprimate, stratificate și estompându-se, exact ca propriile noastre amintiri. DeepSeek-OCR ne arată că această viziune nu este science-fiction, ci o realitate tehnică funcțională, gata să fie explorată și extinsă. Codurile și greutățile modelului sunt accesibile public pe GitHub, invitând comunitatea să construiască pe această fundație fascinantă.