Qwen a lansat o serie inovatoare de modele de embedding și reranking, numită Qwen3 Embedding, care se remarcă prin performanța sa de ultimă oră și accesibilitatea sa.
1. Introducere
În lumea în continuă evoluție a modelelor lingvistice mari (LLM-uri), domeniul embeddings text a primit o revigorare recentă. Această serie, construită pe modelul fundamental Qwen3, oferă o abordare puternică pentru sarcinile de text embedding, regăsire (retrieval) și reranking. Un aspect crucial este licența Apache 2.0 sub care sunt disponibile pe Hugging Face, permițând utilizarea locală sau on-premise și evitând dependența de ecosisteme proprietare.

2. Modele Qwen3 Embedding și reranking
Qwen nu lansează doar un singur model, ci o întreagă suită dedicată embeddings, retrieval și reranking.
Similar cu abordarea Cohere, Qwen a dezvoltat modele dedicate fiecărei sarcini, ajustate fin și chiar integrate cu modelul lingvistic de bază Qwen3. Astfel, seria Qwen3 cuprinde modele de embedding (Qwen3-Embedding-0.6B, Qwen3-Embedding-4B și Qwen3-Embedding-8B) și modele de reranking (Qwen3-Reranker-0.6B, Qwen3-Reranker-4B și Qwen3-Reranker-8B).
Această gamă variată de dimensiuni – de la 0.6B la 8B – permite dezvoltatorilor să aleagă modelul optim în funcție de cerințele proiectului, echilibrând acuratețea cu latența. Toate aceste modele sunt disponibile pe Hugging Face și ModelScope sub licența Apache 2.0, cu codul sursă și raportul tehnic disponibile pe GitHub.
3. Capabilități cheie: versatilitate, flexibilitate și multilingvism
Seria Qwen3 se distinge prin mai multe capabilități remarcabile:
Versatilitate excepțională
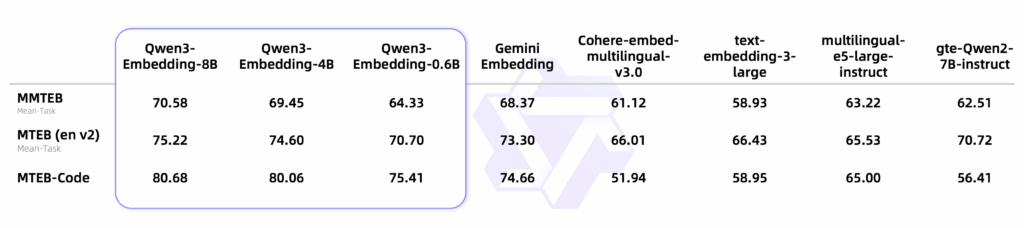
Modelul de embedding de 8B se clasează pe primul loc în clasamentul multilingv MTEB (la data de 5 iunie 2025, cu un scor de 70.58), demonstrând performanțe de ultimă generație (state-of-the-art – SOTA) într-o varietate largă de evaluări. Modelele de reranking, la rândul lor, excelează în sarcinile de regăsire text, îmbunătățind semnificativ relevanța rezultatelor căutării.
Flexibilitate Comprehensivă
Varietatea de dimensiuni (0.6B, 4B, 8B) permite adaptarea la diverse contexte. Suportul pentru Matryoshka Representation Learning (MRL) oferă o flexibilitate suplimentară, permițând ajustarea dimensiunii vectorului embedding la nevoie (64, 128 sau 256) fără a compromite performanța. De asemenea, modelele suportă instrucțiuni definite de utilizator, permițând optimizarea pentru sarcini, limbi sau scenarii specifice.
Capabilitate Multilingvă
Seria Qwen3 Embedding suportă peste 100 de limbi, inclusiv limbaje de programare, oferind capabilități robuste pentru regăsire multilingvă, cross-lingual și pentru cod.
4. Arhitectură și antrenament: bazat pe Qwen3 și LoRA
Modelele Qwen3 Embedding și Reranking sunt construite pe arhitectura solidă a modelului Qwen3. Se utilizează o arhitectură dual-encoder pentru embedding și cross-encoder pentru reranking. Pentru a menține și îmbunătăți capabilitățile modelului de bază, s-a folosit tehnica de fine-tuning LoRA (Low-Rank Adaptation).
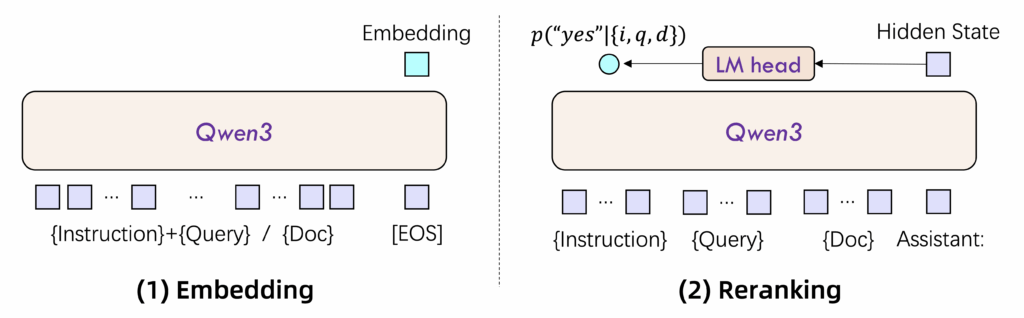
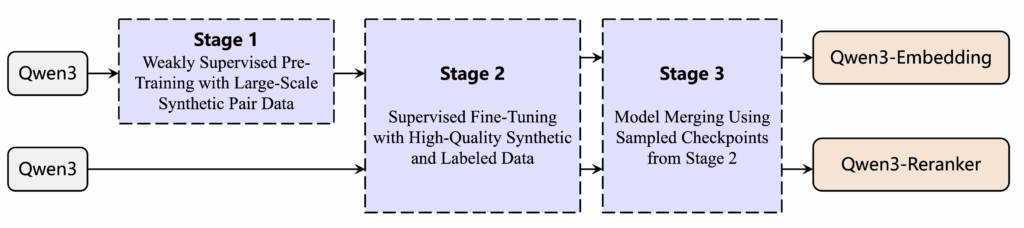
Procesul de antrenament a urmat o abordare bine definită, similară seriei GTE-Qwen, cu antrenament contrastiv prealabil, urmat de antrenament supervizat și integrarea mai multor modele candidate. Pentru reranking, s-a folosit antrenament supervizat direct. Un sistem de prompt adaptabil multi-task a fost folosit pentru a genera perechi de text supervizate pentru antrenamentul embedding-ului.
5. Aspecte tehnice și integrare în sisteme RAG
Modelele Qwen3 Embedding pot suporta lungimi ale secvenței de până la 32K, cu performanțe bune și la 8K, un avantaj semnificativ față de alte modele, precum Gemini Embedding. Disponibilitatea pe Hugging Face și ModelScope, împreună cu posibilitatea de rulare locală sau on-premise, oferă o flexibilitate remarcabilă.
Aceste modele sunt concepute pentru a fi integrate în sisteme RAG (Retrieval Augmented Generation) și alte sisteme similare. Alegerea dimensiunii potrivite a modelului permite optimizarea echilibrului dintre acuratețe și latență, un aspect crucial în aplicațiile RAG.
6. Concluzie
Lansarea seriei Qwen3 Embedding reprezintă un pas înainte semnificativ în domeniul embeddings text și reranking. Oferind modele open-source, de ultimă generație, cu suport multilingv extins și o flexibilitate sporită, Qwen pune la dispoziția dezvoltatorilor instrumente puternice pentru construirea de aplicații avansate, în special în domeniul RAG. Disponibilitatea largă și capacitatea de a rula modelele local încurajează experimentarea și adoptarea pe scară largă, marcând o nouă eră pentru embeddings text și reranking.