Microsoft a lansat oficial noile sale modele din seria Phi-4: Phi-4-mini (3.8B) și Phi-4-multimodal (5.6B) — sub licența MIT. Aceste modele sunt concepute nu numai pentru a depăși limitele în domeniul raționamentului, suportului multilingv și matematicii, dar vin și cu funcții interesante precum apelarea funcțiilor și implementarea modelului cuantificat.
1. Prezentare generală a modelelor Phi-4
Seria Phi-4 de la Microsoft se bazează pe raționamentul avansat al predecesorului său (modelul de 14B) și prezintă două modele:
Phi-4-Multimodal: un model complet multimodal care integrează text, viziune și audio. Acesta folosește o „Mixture of LoRAs”, astfel odal care integrează text, viziune și audio. Acesta folosește o „Mixture of LoRAs”, astfel încât să puteți adăuga adaptoare specifice modalității fără a re-antrena modelul de bază.
Phi-4-Mini: 3,8 miliarde de parametri într-un model compact care oferă suport multilingv îmbunătățit, capacități puternice de raționament și chiar apelare de funcții — totul într-o arhitectură compactă
Ambele modele AI sunt acum disponibile pe platforme precum Hugging Face, Azure AI Foundry Model Catalog, GitHub și Ollama.
2. Arhitecturi și caracteristici cheie
Phi-4-Multimodal este bazat pe „Mixture of LoRAs” și care capacități de gnerare text, video și audio.
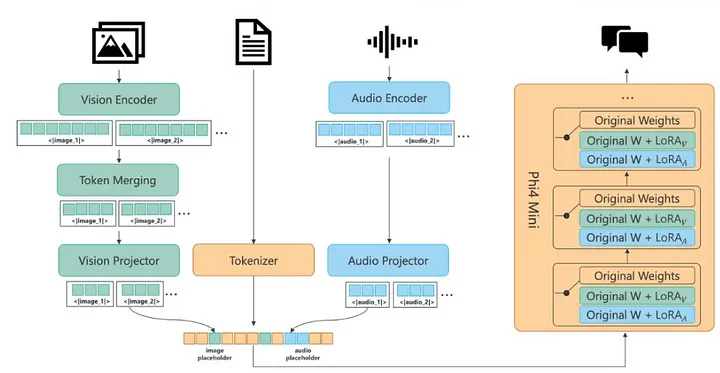
Pentru partea de computer vision, Phi-4-Multimodal folosește un encoder de imagineSigLIP-400M și multi-crop dinamic pentru o mai bună înțelegere a imaginii.
Pentru partea audio generativă se folosește o rețea de convoluție cu 3 straturi, 24 de blocuri cu o rată de token de 80 ms care generează o performanță de top în clasamentul OpenASR al modelelor AI multimodale.
Phi-4-Mini are doar 3.8 miliarde de parametri și se bazează pe 32 de straturi Transformer și pe atenție de grup (GQA) cu 24 de capete de interogare și 8 capete cheie/valoare.
Phi-4-Mini are un vocabular de 200k token orientat spre aplicațiile multilingve. A fost atrenat cu date disponibile online cu focus pe matematică și codare.
3. Antrenament și performanțe
Procesul de antrenament pentru aceste modele implică mai multe etape:
3.1. Antrenament lingvistic
Au fost folosite 5 trilioane de token-uri care au inclus date de apelare a funcțiilor, rezumare și urmărire a instrucțiunilor. Pentru antrenarea multimodală (computer vision și audio) au fost făcute mai multe sesiuni de antrenament (4 video, 2 audio și unul comun video și audio).
Phi 4 este mult mai mic decât Gemini 2.0 Flash, dar în schimb este open use și poate fi instalat direct pe dispozitivele personale fără grija pierderii confidențialității datelor importante.
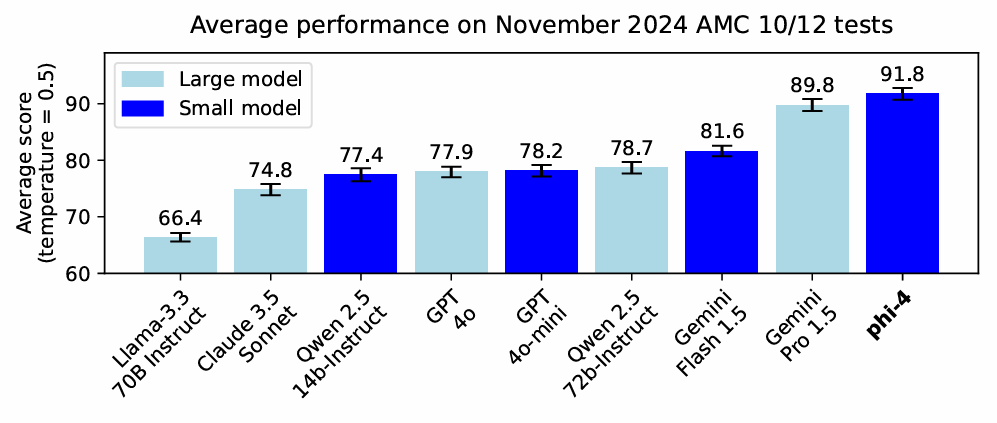
3.2. Antrenament de raționament
Pentru antrenamentul de raționament au fost folosite 60 miliarde de token-uri de tip lanț de judecată, urmată de un reglaj fin pe 200k tokenuri atent selecționate și o reantrenare de tip DPO pe 300k eșantioane de calitate înaltă.
În concecință modelele din seria Phi 4 excelează la taskuri de tip OCR sau analiză grafice, identificare vocală și urmare instrucțiuni, calcule matematice și codare.
Phi 4 nu se compară cu modele mari de raționament precum QwQ-32B sau DeepSeek-R1, dar pentru un SML se descurcă de minune.
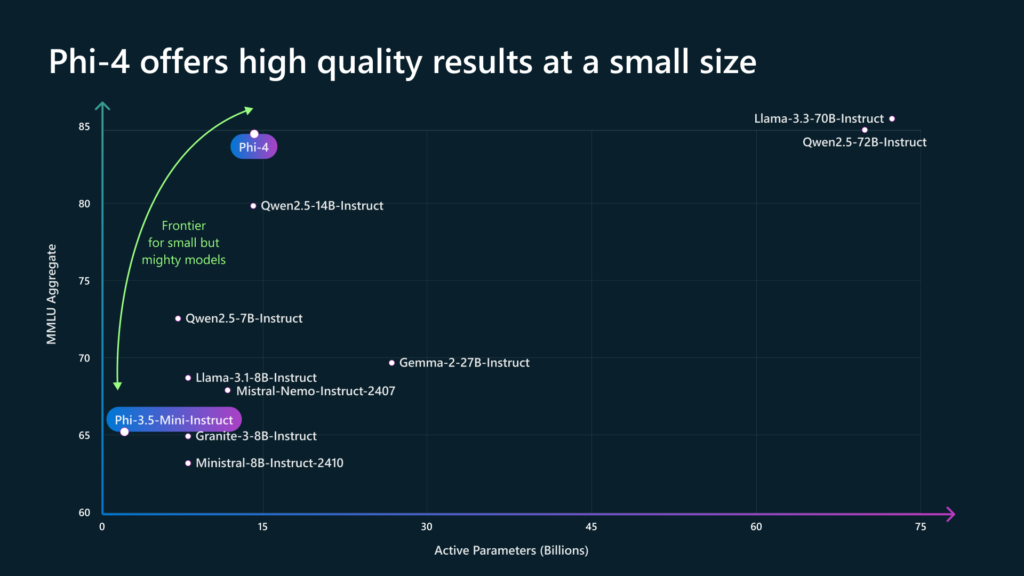
4. Exemple de utilizare
Seria Phi 4 este destinată situațiilor de utilizare cu resurse restrânse (memorie și putere de calcul) pentru răspunsuri rapide legate în principal de analiza imaginilor sau a vocii și apelarea funcțiilor pentru situații specifice.
Modelele pot fi instalare pe echipamente fără caracteristici tehnice performante, de exemplu chiar pe telefoanele personale, dar poate fi utilizat și din cloud.
4.1. Utilizare prin Azure AI Foundry
Azure AI Foundry oferă un mediu perfect pentru implementarea și testarea acestor modele.
Pentru aceasta este nevoie să accesăm Portalul cloud Azure și să adăugăm un proiect nou în care să alocăm un model AI – de exemplu fie Phi-4-Mini.
Apoi putem folosi python:
# pip install azure-ai-inference
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
api_key = os.getenv("AZURE_INFERENCE_CREDENTIAL", '')
if not api_key:
raise Exception("A key should be provided to invoke the endpoint")
client = ChatCompletionsClient(
endpoint='https://<>.models.ai.azure.com',
credential=AzureKeyCredential(api_key)
)
model_info = client.get_model_info()
print("Model name:", model_info.model_name)
print("Model type:", model_info.model_type)
print("Model provider name:", model_info.model_provider_name)
payload = {}
response = client.complete(payload)
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print(" Prompt tokens:", response.usage.prompt_tokens)
print(" Total tokens:", response.usage.total_tokens)
print(" Completion tokens:", response.usage.completion_tokens)4.2. Utilizare locală
Pentru a rula Phi-4-mini local putem folosi următorul cod python și curl:
# Install vLLM from pip:
pip install vllm
# Load and run the model:
vllm serve "microsoft/Phi-4-mini-instruct"
# Call the server using curl:
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "microsoft/Phi-4-mini-instruct",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}4.3. Folosirea funcțiilor
Phi-4 funcționează excelent împreună cu funcțiile predefinite. Este un model care poate rezolva multe din sarcinile repetitive, unde viteza de decizie este importantă și costurile trebuie ținute în frâu.
Un exemplu python de apelare a funcțiilor este următorul:
import torch
import json
import random
import string
import re
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig,pipeline,AutoTokenizer
model_path = "Your Phi-4-mini location"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
attn_implementation="flash_attention_2",
torch_dtype="auto",
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Tools should be a list of functions stored in json format
tools = [
{
"name": "get_match_result",
"description": "get match result",
"parameters": {
"match": {
"description": "The name of the match",
"type": "str",
"default": "Arsenal vs ManCity"
}
}
},
]
# Function implementations
def get_match_result(match: str) -> str:
# This would be replaced by a weather API
match_data = {
"Arsenal vs ManCity": "1:1",
"Chelsea vs ManUnited": "0:2"
}
return match_data.get(match, "I don't know")
messages = [
{
"role": "system",
"content": "You are a helpful assistant",
"tools": json.dumps(tools), # pass the tools into system message using tools argument
},
{
"role": "user",
"content": "What is the result of Arsenal vs ManCity today?"
}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_dict=True, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
output = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(output[0][len(inputs["input_ids"][0]):]))
tokenizer.batch_decode(output)
response = tokenizer.decode(output[0][len(inputs["input_ids"][0]):], skip_special_tokens=True)
tool_call_id = ''.join(random.choices(string.ascii_letters + string.digits, k=9))
messages.append({"role": "assistant", "tool_calls": [{"type": "function", "id": tool_call_id, "function": response}]})
try :
tool_call = json.loads(response)[0]
except :
json_part = re.search(r'\[.*\]', response, re.DOTALL).group(0)
tool_call = json.loads(json_part)[0]
function_name = tool_call["name"]
arguments = tool_call["arguments"]
result = get_match_result(**arguments)
messages.append({"role": "tool", "tool_call_id": tool_call_id, "name": "get_match_result", "content": str(result)})
print(messages)4.4. Alte integrări posibile
Microsoft pune la dispoziție modele de cod pentru rezolvarea diferitelor sarcini:
- convertirea în cod a imaginilor;
- extragerea eșantioanelor audio;
- interacțiune vocală;
- traducere automată a vocii;
- analiză de cod;
5. Concluzii
Seria Phi-4, inclusiv Phi-4-Multimodal și Phi-4-Mini, reprezintă un salt cuantic în inovația AI multimodală. Cu suport pentru text, viziune și vorbire — plus funcții precum apelarea funcțiilor și implementarea modelului cuantificat — aceste modele sunt perfect pregătite pentru a alimenta aplicațiile edge, implementările în cloud și tot ce se află între ele.