MiniCPM-V 2.6 este cel mai recent model înzestrad cu computer vision al seriei MiniCPM-V.
Acest model AI ete bazat pe mai cunoscutele modele Qwen2-7b și SigLip-400M și a fost fost antrenat pe 8 miliarde de parametri.
Față de versiunile anterioare, actualul model introduce îmbunătățiri semnificative legate de procesarea și înțelegerea materialelor video sau compuse din mai multe imagini
1. Îmbunătățiri ale MiniCPM-V 2.6
MiniCPM-V 2.6 aduce în sfărșit o mai bună recunoaștere a textelor (OCR) fiind capabil să proceseze imagini de până la 1.8 milioane de pixeli (adica cu o rezoluție de 1344×1344). Testele au arătat că se plasează în această privintă în fața unor modele proprietare mult mai cunoscute precum ChatGPT-4o, ChatGPT-4V sau Google Gemini 1.5 Pro.
Modelul este cotat cu o performanță de 65.2 puncte în testul OpenCompass ceea ce este suprrinzător pentru un model atât de mic.
MiniCPM-V 2.6 generează aproximativ 640 tokeni când procesează o imagine de 1.8M pixeli (aproximativ cu 75% mai puțin decât alte modele AI cu computer vision) ceea ce se traduce în viteză sporită, răspuns rapid, putere consumată și cost scăzut.
2. Cum se poate instala MiniCPM-V 2.6
Modelul AI se poate instala din GitHub, direct din Hugging Face sau din librăria de modele Ollama.
2.1. Modelele disponibile în Ollama
MiniCpm-V este prezent în libraria Ollama sub mai multe variante cuantizate diferit, cu dimensiuni de până la 9.1 GB.
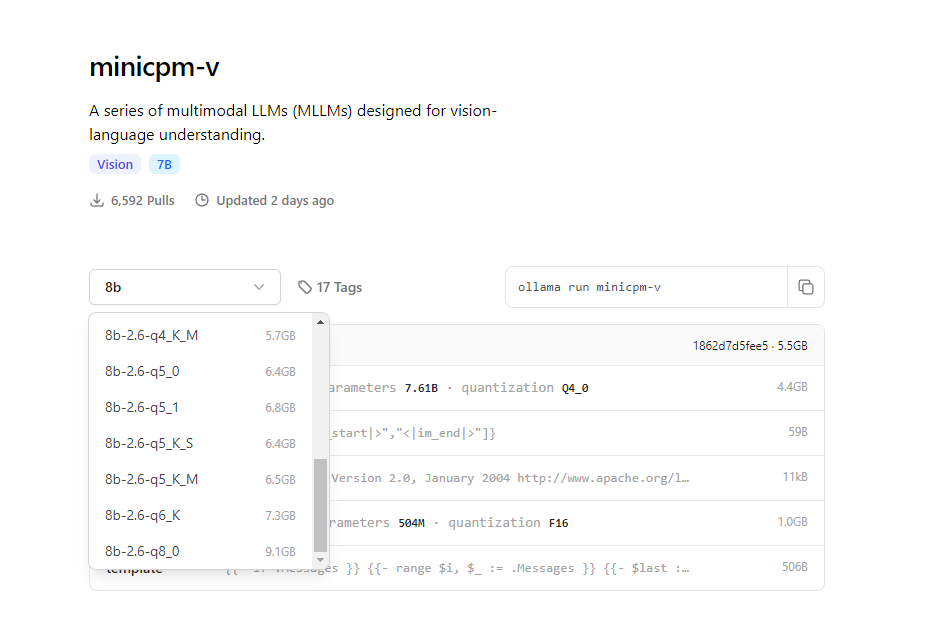
Modelul se poate descărca foarte ușor local (o variantă de aproximativ 5.5 GB) prin comanda
ollama pull minicpm-viar apoi modelul poate fi rulat prin comanda:
ollama run minicpm-v2.2. MiniCpm-V prin GitHub
Repository-ul GitHub poate fi clonat prin comanda:
git clone https://github.com/OpenBMB/MiniCPM-V.gitiar apoi se poate utiliza orice fel de cod pe modelul:
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
torch.manual_seed(0)
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image = Image.open('./test_image.jpeg').convert('RGB')
# First round chat
question = "Tell me the model of this aircraft."
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
# Second round chat
# pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["Introduce something about Airbus A380."]})
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
MiniCPM-V 2.6 vine atât în variantele optimizate pentru procesare cu GPU, dar și pentru cele care folosesc CPU în versiuni de dimensiuni mai mici.
| Model | Device | Memorie | Descriere |
|---|---|---|---|
| MiniCPM-V 2.6 | GPU | 17 GB | Cea mai recentă versiune, cu cele mai bune perfromanțe folosită împreună cu o placă video performantă. |
| MiniCPM-V 2.6 gguf | CPU | 6 GB | Versiunea gguf, cu cerițe mici de memorie, dar viteză mare de rulare pe CPU. |
| MiniCPM-V 2.6 int4 | GPU | 7 GB | Versiunea cu coantizare int4 pentru plăci video uzuale. |
2.3. MiniCpm-V prin Hugging Face
Pentru utilizarea modelului cu Python vor trebui instalate înainte librăriile:
Pillow==10.1.0
torch==2.1.2
torchvision==0.16.2
transformers==4.40.0
sentencepiece==0.1.99
decordUn exemplu de cod de folosire MiniCPM-V 2.6 este următorul:
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': [image, question]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(res)
## if you want to use streaming, please make sure sampling=True and stream=True
## the model.chat will return a generator
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
stream=True
)
generated_text = ""
for new_text in res:
generated_text += new_text
print(new_text, flush=True, end='')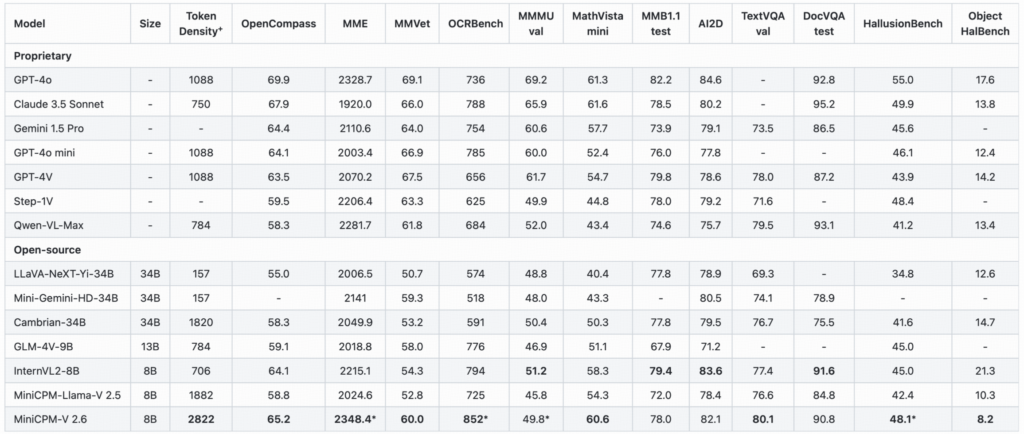
Tabelul de rezultate de performanță ne arată ca MiniCPM-V 2.6 excelează în identificarea textelor OCR și procesarea de tip multimodala (video și imagini).
3. Testare computer vision
Pentru testarea modelului, am rulat modelul prin serverul Ollama instalat local în varianta de mijloc, de 5.5 GB.
Modelul a răspuns extrem de rapid pentru toate procesările cerute.
Pentru tabelul de rezultate de performanță din predenta imagine am cerut modelului AI să o descrie, iar răspunsul a fost:
The table presents a comprehensive comparison of various AI models across different metrics. These metrics include proprietary accuracy, open source model size and performance on the OpenCompass
benchmark for vision tasks (MMVU), memory use in GB, video classification time in seconds, validation dataset score from the MMUv1 mini test set, human evaluation scores using TVEQA, document
hallmarks by Hallbench, image recognition results with ImageNet-2013 class 67% accuracy on MNIST and HandHallbench performance. The table lists several models including the GPT-4o, CLIP-3Sonnentag,
Gemini Pro Series (not listed in English), Step-IV-V, and many others up to 859 rows of data under different columns representing various metrics for each model or series compared.Următorul test urmărește procesarea unei imagini de tip chart/reprezentare grafică:
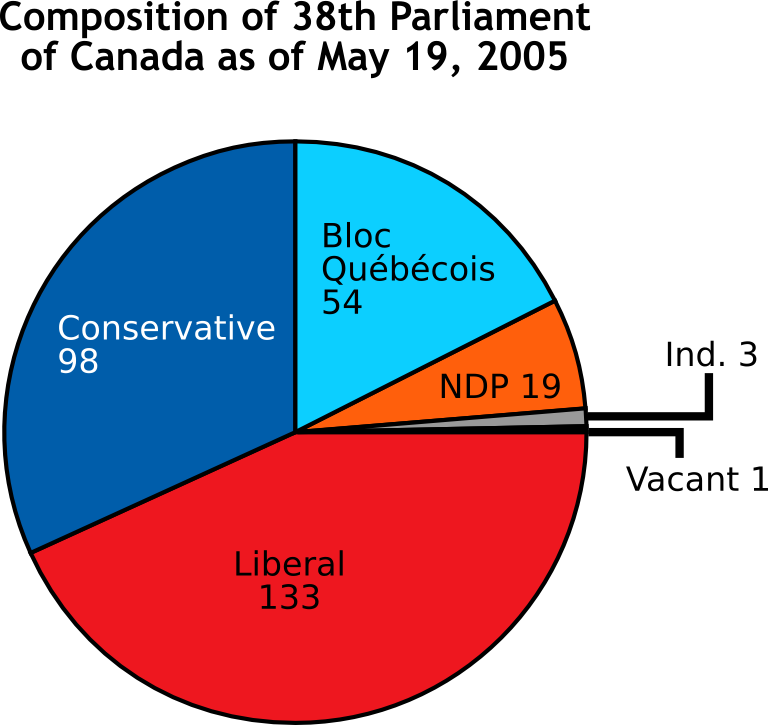
- Tip de imagine: Diagramă pie (diagramă circulară)
- Titlu: Compohetion of 38th Parliament of Canada as of May 19, 2005
- Conținut: Imaginea este un diagramă pie care prezintă conținutul Parlamentului al 38-a a Canadă la data de 19 mai 2005. Analiza imaginii ne permite să vedem componentele principale ale
parlamentului:
* Conservative: Reprezentată în albastru, imaginea indică că partidul conservator are 98 de membri.
* Liberali: Dominanța alianței liberale este evidentă, având 133 de membri și afișată în roşie intense.
Îi vom cere modelului AI să descrie imaginea și să ne spună (dacă le identifică) câte oi vede:
>>> describe image ./sheeps.webp
The image depicts a serene pastoral scene featuring three sheep grazing on lush green grass. One of the sheep is white, while the other two are brown and black respectively, providing contrast to
each other in terms of coloration.
Each sheep appears content and relaxed as they stand or sit amidst the verdant field. The background consists of gently rolling hills that fade into a soft blue sky scattered with wispy clouds. In
one corner of the image, there's a quaint wooden fence partially visible behind some trees, adding to the rural charm.
The overall atmosphere conveyed by this image is peaceful and idyllic, capturing the essence of pastoral life in an unspoiled natural setting.
>>> how many sheeps are in image ./sheeps.webp
3
Pentru testul OCR am furnizat modelului MiniCPM-V 2.6 imaginea unui zid pe care au fost desenate mai multe cuvinte:

iar interpretarea a fost următoarea:
The image shows a black and white photograph of the side of a building with bold, handwritten-style text painted on its brick wall. The message conveyed by the words is "WORDS DO NOT MEAN ANYTHING
TODAY." This statement appears to be an expression or commentary about language in contemporary society.
In terms of composition, this photo employs high contrast between the black paint and white bricks for visual emphasis. Additionally, there's a subtle background element - a crest with text on it
that reads "1879" which adds some historical context but is less prominent than the main message painted over the wall.
The overall tone set by this image can be interpreted as critical or reflective of societal issues concerning communication and meaning in modern times.După cum se vede, modelul a identificat corect textul chiar dacă acesta era scris cu mărimi diferite, din perspectivă și chiar fără un contur clar al literelor.
4. Concluzii
MiniCPM-V 2.6 este un model AI ușor de instalat și de folosit chiar și pe dispozitive lipsite de mijloace puternice de procesare grafică. Modelul poate fi integrat în funcții de analiză de imagini, de recunoaștere de text (OCR) sau interpretare a contextului și furnizează răspunsuri rapide.
Există o gamă largă de aplicabilitate:
- integrare computer vision la roboți;
- automatizare identificare erori la produse;
- ghidaj automat pe bază de simboluri;
- descriere imagini;
- analiză comparată a imaginilor;
- extragere și identificare (OCR) a textului din imagini;
- etc.