Qwen a lansat noua serie de modele Qwen2-VL cu capacități revoluționare de computer vision și eficacitate ridicată.
Avantajele Qwen2-vl
Qwen2-VL este capabil să analizeze materiale video de peste 20 de minute într-o formă conversațională pe bază de dialog cu utilizatorul.
Modelul AI poate fi integrat în dispozitive mobile (tablete, telefoane inteligente) sau chiar roboți pentru a asigura controlul acestora pe baza unor operațiuni automate sau pe baza analizei în timp real a contextului.
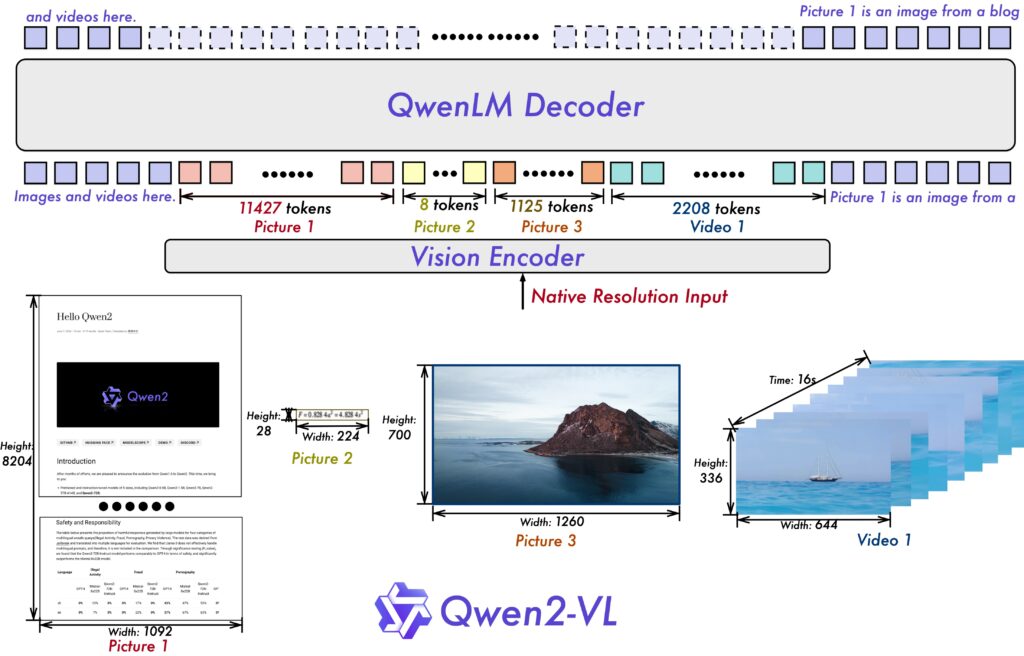
Deși modelele au fost antrenate în mod specific pentru limba engleză și chineză, ele sunt capabile să înțeleagă toate limbile europene.
Limitările modelului Qwen2-vl
Modelul nu este capabil să analizeze secțiunea audio din materiale video. De asemenea antrenarea modelului s-a făcut pe seturi de date dinainte de iunie 2023, deci e posibil ca materialele mai recente să nu fie recunoscute cu exactitate.
Testarea modelului AI Qwen2 -vl 2B
Modelul 2B are o dimensiune de aproximativ 4 GB și poate fi instalat ușor pe un dispozitiv local, cu caracteristici tehnice mai slabe.
Pentru a rula modelul este necesat mai întâi să instalăm librăriile standard:
pip install torch
pip install git+https://github.com/huggingface/transformers
pip install accelerate huggingface_hub tiktoken bitsandbytes torchvision
pip install qwen-vl-utils
pip install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidiaCodul dat ca exemplul de Qwen este:
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-2B-Instruct", torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2-VL-2B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)Imaginea analizată este:

iar răspunsul modelului este:
['The image depicts a serene beach scene with a woman and her dog. The woman is sitting on the sand, wearing a plaid shirt and black pants, and appears to be smiling. She is holding up her hand in a high-five gesture towards the dog, which is also sitting on the sand. The dog has a harness on, and its front paws are raised in a playful manner. The background shows the ocean with gentle waves, and the sky is clear with a soft glow from the setting or rising sun, casting a warm light over the entire scene. The overall atmosphere is peaceful and joyful.']Am testat modelul pe imagini mai recente:

Modelul este capabil să recunoască tricolorul României în imagine:
['The image shows a group of soccer players on a field, celebrating together. One player is holding a large Romanian flag draped around him, indicating that they might be celebrating a victory or achievement related to Romania. The players are wearing yellow uniforms with blue numbers and the Romanian national emblem on their chests. The field is covered in yellow petals, suggesting that this could be a special occasion or a celebration of some sort. The players are standing on the grass, and there are other people in the background, likely coaches or staff members. The overall atmosphere appears to be one of joy and triumph.']
['The image is a black-and-white photograph featuring two men, both wearing bowler hats and suits. The man on the left has a mustache and is smiling, while the man on the right also has a mustache and is also smiling. Both men have autographs on their suits, signed by Stan Laurel and Oliver Hardy. The background is plain, focusing attention on the two individuals.']Pe lângă descrierea corectă a imaginii, Qwen2-vl este capabil să recunoască cele 2 personaje celebre.

['The image is a black and white photograph featuring a man standing next to a classic car in what appears to be an outdoor parking lot. The man is dressed in a dark suit and appears to be in a contemplative or serious mood, with his hands resting on the hood of the car. The car itself is a vintage model, likely from the 1960s or 1970s, characterized by its sleek design and chrome accents. In the background, there are other cars parked in a row, suggesting that this might be a popular or well-known location for parking. The overall atmosphere of the image is somewhat nostalgic']Absolut remarcabil, chiar dacă imaginea nu conține suficiente informații despre mașină, Qwen2-vl apreciază că este vorba de un model produs în perioada 1960-1970.
Concluzii: Qwen2-vl este un model AI absolut fabulos
Analiza imaginilor arată că Qwen2-vl chair și în cea mai mică versiune a lui de 2B se descurcă extraordinar de bine, fiind capabil să recunoască personaje celebre sau chiar obiectele din imagini.
Qwen2-vl pare că se descurcă chiar mai bine decât Florence-2, modelui AI cu computer vision propus de Microsoft.