Florence-2 lansat de Microsoft în iunie 2024 este un LLM multimodal care permite analiza imaginilor, generarea de descrieri, detecția de obiecte și OCRizarea textului.
Modelul nu ocupă prea mult spațiu (aproximativ 1.5 GB) ceea ce îl face ușor de instalat și pe dispozitive locale.
Ce poate face Florence-2?
Florence-2 este capabil să lucreze pe diferite nivele semantice și de spațialitate care ii permit să recunoască obiectele și semnificația lor, dar și să distingă într-o scenă relațiile dintre aceste obiecte.
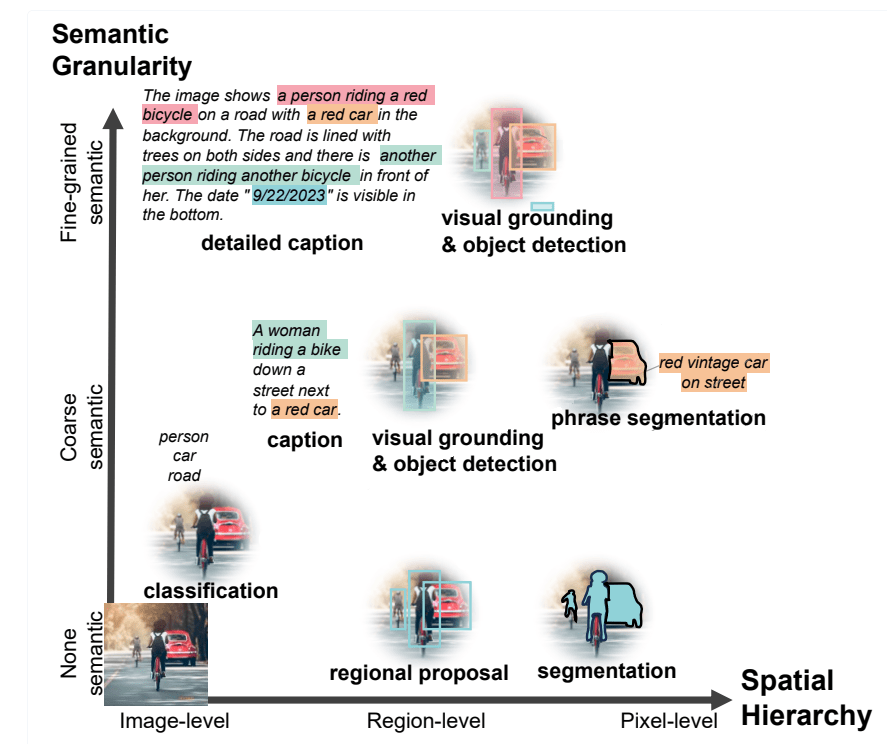
Cum funcționează Florence-2?
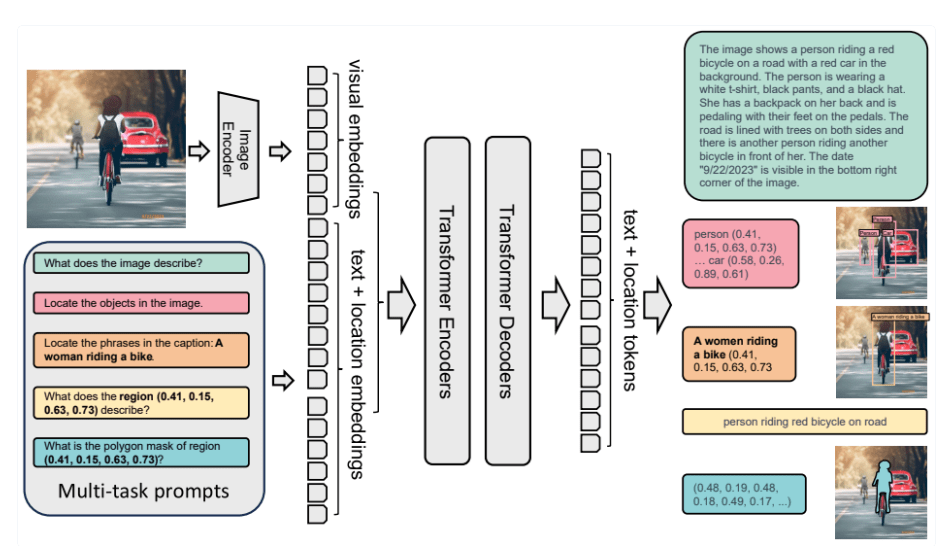
Modelul Florence-2 are o arhitectură simplă, bazată pe instrucțiuni de la utilizator care generează răspunsuri în format text referitoare la imagine.
Modelul permite identificarea contururilor, regiunilor folosind o arhitectură seq2seq2 cu parametri vizuali și de tip text.
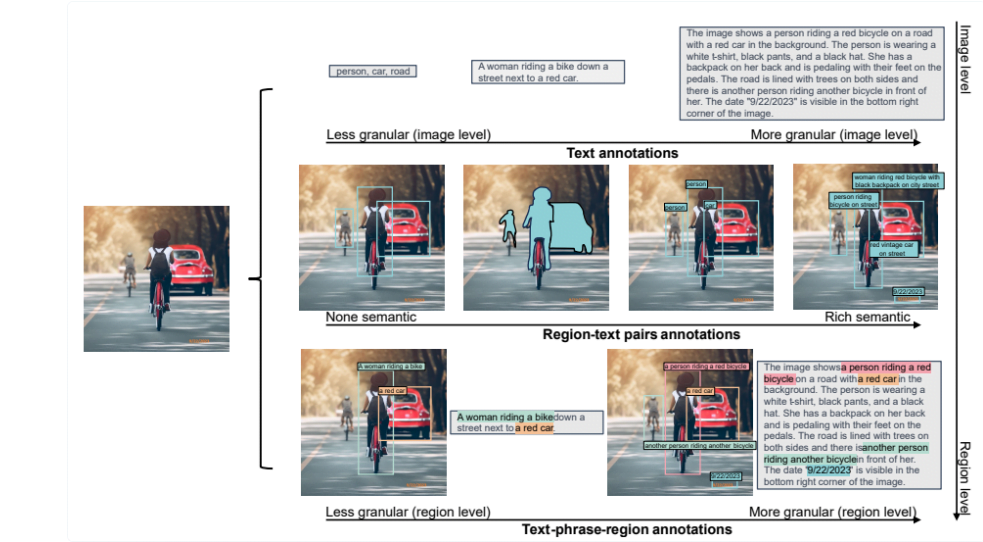
Însă pentru a corela obiectele identificate cu semnificația lor, Florence-2 a avut nevoie de un set de date de antrenare extraordinar. Microsoft a folosit un set de 126 de milioane de imagini peste care au fost adăugate 5.4 miliarde de observații de tip text, care a necesitat un mare volulum de muncă umană:
Cum putem folosi Florence-2?
Modelul este disponbil sub licență MIT care permite utilizarea în scop comercial. Pentru instalare va trebui să apelăm la mai câteva dependețe:
pip install transformers timm flash_attn einopsdin care singura care pune probleme este flash_attn care în cazul testelor noastre, pe un sistem de operare Windows 11 a avut nevoie de aproape o oră pentru a fi compilată.
Dar odată trecut acest hop putem trece direct la programare:
from transformers import AutoProcessor, AutoModelForCausalLM
from PIL import Image
import requests
import copy
model_id = 'microsoft/Florence-2-large'
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True).eval().cuda()
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
def run_example(task_prompt, text_input=None):
if text_input is None:
prompt = task_prompt
else:
prompt = task_prompt + text_input
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
input_ids=inputs["input_ids"].cuda(),
pixel_values=inputs["pixel_values"].cuda(),
max_new_tokens=1024,
early_stopping=False,
do_sample=False,
num_beams=3,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(
generated_text,
task=task_prompt,
image_size=(image.width, image.height)
)
return parsed_answer
image = Image.open("imagine1.jpg")
task_prompt = '<CAPTION>'
print(run_example(task_prompt)["<CAPTION>"].strip())Pentru început vom dori ca Florence-2 să genereze descrieri pentru 2 imagini folosite deja pentru testarea modelului LLAVA 1.6
Pentru început imaginea 1:

Răspunsul Florence-2 este mult mai scurt decât al LLAMA 1.6, dar cu toate acestea corect:

A large cruise ship in the middle of the ocean.
Cu toate acestea Florence-2 permite 3 nivele de descrieri: Caption, Detailed_caption și More_detailed_caption.
Dacă alegem varianta cea mai complexă descrierea devine:
The image is an aerial view of a large cruise ship sailing in the ocean. The ship is white with multiple levels and decks, and it appears to be a luxury cruise ship. The deck is divided into different sections, each with a different layout and color scheme. The top level has multiple levels of amenities, including a large pool, a spa, a restaurant, and a bar, while the bottom level has a smaller deck with multiple lounge areas. There are also several smaller balconies and balconies on the sides of the ship, as well as a large dome-shaped structure on the top deck.
The ship is sailing on the blue ocean, with the horizon visible in the background. The sky is clear and blue, and the water is calm, with small waves visible on the surface. The overall mood of the image is peaceful and serene.
A 2-a imagine este o livada cu meri:

Pentru aceasta Florence-2 ne dă următoarea descriere:
The image shows a large field of apples with rows of trees on either side. The apples are scattered all over the ground, covering the entire ground. The trees are tall and slender, with their branches reaching up towards the sky. The leaves of the trees are a mix of red, orange, and yellow, indicating that the apples are ripe and ready to be picked. The field is surrounded by hills and trees, and the sky is overcast. The overall mood of the image is peaceful and serene.
Capacități de OCRizare
La fel ca și la testarea LLAVA 13B 1.6 vom testa capacitatea modelului Florece-2 de a identifica textul care apare în diferite imagini, de rezoluții și aspecte diferite.
Pentru început vom folosi imaginea:

pe care modelul o identifică fără ezitări:

It was the best oftimes, it was the worstof times, itwas the ageof wisdom,it was theage of foolishness…
A doua imagine, de calitate mai mai slabă a produs dificultăți în recunoașterea textului,

dar Florence-2 răspunde cu:

POWER SUPPLYTHE CALCULATOR IS POWERED BYSOLAR CELL AND A BATTERY FORBACKUP. THE DISPLAY WILL DIM WHENTHE BATTERy NEEDS TO BE REPLACED.THE „+” SIGN OF EACH BATTERY MUSTSHOW UPWARD WHEN INSERTED.
Răspuns excelent, fără halucinații sau reinterpretări.
La imaginea 3, Florence-2 nu a avut nici o problemă în a detecta textul:


WILDLIFE
Concluzie
Florence-2 este un model extraordinar cu rezultate fiabile care poate fi folosit în numeroase aplicații chiar instalat local pe propriul dispozitiv.